

Modern data pipelines have become more business-critical than ever. Every company today is a data company, looking to leverage data analytics as a competitive advantage. But the complexity of the modern data stack imposes some significant challenges that are hindering organizations from realizing their goals and realizing the value of data.
TDWI recently hosted an expert panel on modern data pipelines, moderated by Fern Halper, VP and Senior Director of Advanced Analytics at TDWI, with guests Kunal Agarwal, Co-Founder and CEO of Unravel Data, and Krish Krishnan, Founder of Sixth Sense Advisors.
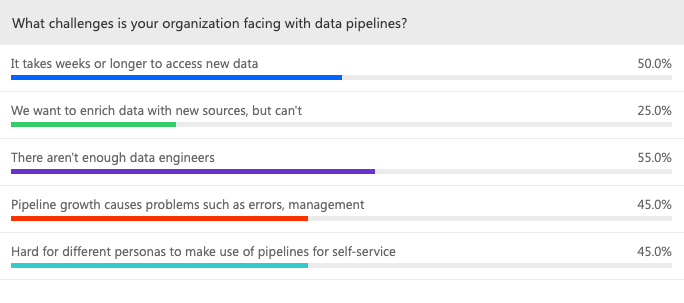
Dr. Halper opened the discussion with a quick overview of the trends she’s seeing in the changing data landscape, characteristics of the modern data pipeline (automation, universal connectivity, scalable/flexible/fast, comprehensive and cloud-native), and some of the challenges with pipeline processes. Data takes weeks or longer to access new data. Organizations want to enrich data with new data sources, but can’t. There aren’t enough data engineers. Pipeline growth causes problems such as errors and management. It’s hard for different personas to make use of pipelines for self-service. A quick poll of attendees showed a pretty even split among the different challenges.
The panel was asked how they define a modern data pipeline, and what challenges their customers have that modern pipelines help solve.
Kunal talked about the different use cases data-driven companies have for their data to help define what a pipeline is. Banks are using big data to detect and prevent fraud, retailers are running multidimensional recommendation engines (products, price). Software companies are measuring their SaaS subscriptions.
“All these decisions, and all these insights, are now gotten through data products. And data pipelines are the backbone of running any of these business-critical processes,” he said. “So, ultimately, a data pipeline is a sequence of actions that’s gathering, collecting, moving this data from all the different sources to a destination. And the destination could be a data product or a dashboard. And a pipeline is all the stages it takes to clean up the data, transform the data, connect it together, and give it to the data scientist or business analyst to be able to make use of it.”
He said that with the increased volume, velocity, and variety of data, modern data pipelines need to be scalable and extensible—to add new data sources, to move to a different processing paradigm, for example. “And there are tons of vendors who are trying to crack this problem in unique ways. But besides the tools, it should all go back to what you’re trying to achieve, and what you’re trying to drive from the data, that dictates what kind of data pipeline or architecture you should have,” Kunal said.
Krish sees the modern data pipeline as the integration point enabling the true multi-cloud vision. It’s no longer just one system or another, but a mix-and-match “system of systems.” And the challenges revolve around moving workloads to the cloud. “If a company is an on-premises shop and they’re going to the cloud, it’s a laborious exercise,” he said. “There is no universal lift-and-shift mechanism for going to the cloud. That’s where pipelines come into play.”
Observability and the Modern Data Pipeline
The panel discussed the components and capabilities of the modern data pipeline, again circling back to the challenges spawned by the increased complexity. Kunal noted that one common capability among organizations that are running modern data pipelines successfully is observability.
“One key component we see along all the different stages of a pipeline is observability. Observability helps you ultimately improve reliability of these pipelines—that they work on time, every time—and improve the productivity of all the data team members. The poll results show that there aren’t enough data engineers, the demand far exceeds the supply. And what we see is that the data engineers who are present are spending more than 50% of their time just firefighting issues. So observability can help you eliminate—or at least get ahead of—all these different issues. And last but not least, we see that businesses tame their data ambitions by looking at their ballooning cloud bills and cloud costs. And that also happens because of the complexity that these data technologies present. Observability can also help get control and governance around cloud costs so you can start to scale your data operations in a much more efficient manner.”
See the entire panel discussion on demand
Watch the entire conversation with Kunal, Krish, and Fern from TDWI’s Expert Panel: Modern Data Pipelines on-demand replay.