

The Complexities of Code Optimization in Databricks: Problems, Challenges and Solutions
Databricks, with its unified analytics platform, offers powerful capabilities for big data processing and machine learning. However, with great power comes great responsibility – and in this case, the responsibility of efficient code optimization.
This blog post explores the complexities of code optimization in Databricks across SQL, Python, and Scala, the difficulties in diagnosing and resolving issues, and how automated solutions can simplify this process.
The Databricks Code Optimization Puzzle
1. Spark SQL Optimization Challenges
Problem: Inefficient Spark SQL queries can lead to excessive shuffling, out-of-memory errors, and slow execution times.
Diagnosis Challenge: Identifying the root cause of a slow Spark SQL query is complex. Is it due to poor join conditions, suboptimal partitioning, or inefficient use of Spark’s catalyst optimizer? The Spark UI provides a wealth of information, but parsing through stages, tasks, and shuffles to pinpoint the exact issue requires deep expertise and time.
Resolution Difficulty: Optimizing Spark SQL often involves a delicate balance. Techniques like broadcast joins might work well for small-to-medium datasets but fail spectacularly for large ones. Each optimization technique needs to be carefully tested across various data scales, which is time-consuming and can lead to performance regressions if not done meticulously.
2. Python UDF Performance Issues
Problem: While Python UDFs (User-Defined Functions) offer flexibility, they can be a major performance bottleneck due to serialization overhead and lack of Spark’s optimizations.
Diagnosis Challenge: The impact of Python UDFs isn’t always immediately apparent. A UDF that works well on a small dataset might become a significant bottleneck as data volumes grow. Identifying which UDFs are causing issues and why requires careful profiling and analysis of Spark jobs.
Resolution Difficulty: Optimizing Python UDFs often involves rewriting them in Scala or using Pandas UDFs, which requires a different skill set. Balancing between code readability, maintainability, and performance becomes a significant challenge, especially in teams with varying levels of Spark expertise.
3. Scala Code Complexity
Problem: While Scala can offer performance benefits, complex Scala code can lead to issues like object serialization problems, garbage collection pauses, and difficulty in code maintenance.
Diagnosis Challenge: Scala’s powerful features, like lazy evaluation and implicits, can make it difficult to trace the execution flow and identify performance bottlenecks. Issues like serialization problems might only appear in production environments, making them particularly challenging to diagnose.
Resolution Difficulty: Optimizing Scala code often requires a deep understanding of both Scala and the internals of Spark. Solutions might involve changing fundamental aspects of the code structure, which can be risky and time-consuming. Balancing between idiomatic Scala and Spark-friendly code is an ongoing challenge.
4. Memory Management Across Languages
Problem: Inefficient memory management, particularly in long-running Spark applications, can lead to out-of-memory errors or degraded performance over time.
Diagnosis Challenge: Memory issues in Databricks can be particularly elusive. Is the problem in the JVM heap, off-heap memory, or perhaps in Python’s memory management? Understanding the interplay between Spark’s memory management and the specifics of SQL, Python, and Scala requires expertise in all these areas.
Resolution Difficulty: Resolving memory issues often involves a combination of code optimization, configuration tuning, and sometimes fundamental architectural changes. This process can be lengthy and may require multiple iterations of testing in production-like environments.
The Manual Optimization Struggle
Traditionally, addressing these challenges involves a cycle of:
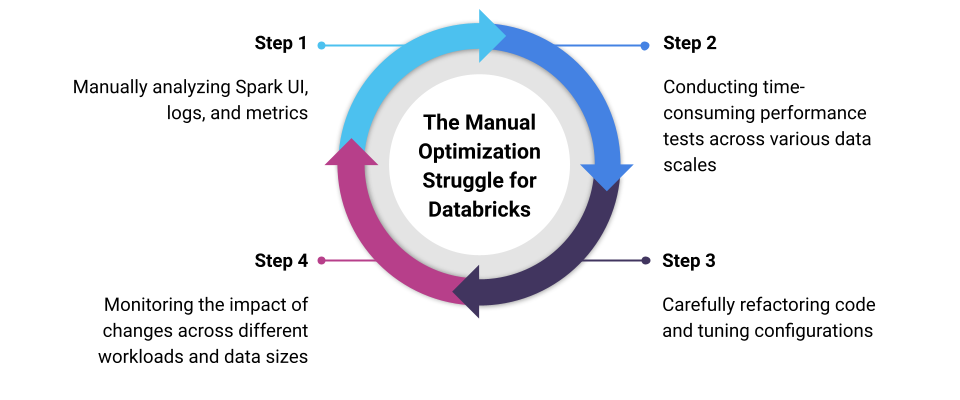
1. Manually analyzing Spark UI, logs, and metrics
2. Conducting time-consuming performance tests across various data scales
3. Carefully refactoring code and tuning configurations
4. Monitoring the impact of changes across different workloads and data sizes
5. Rinse and repeat
This process is not only time-consuming but also requires a rare combination of skills across SQL, Python, Scala, and Spark internals. Even for experts, keeping up with the latest best practices and Databricks features is an ongoing challenge.
Leveraging Automation for Databricks Optimization
Given the complexities and ongoing nature of these challenges, many organizations are turning to automated solutions to streamline their Databricks optimization efforts. Tools like Unravel can help by:
1. Cross-Language Performance Monitoring: Automatically tracking performance metrics across SQL, Python, and Scala code in a unified manner.
2. Intelligent Bottleneck Detection: Using machine learning to identify performance bottlenecks, whether they’re in SQL queries, Python UDFs, or Scala code.
3. Root Cause Analysis: Quickly pinpointing the source of performance issues, whether they’re related to code structure, data skew, or resource allocation.
4. Code-Aware Optimization Recommendations: Providing language-specific suggestions for code improvements, such as replacing Python UDFs with Pandas UDFs or optimizing Scala serialization.
5. Predictive Performance Modeling: Estimating the impact of code changes across different data scales before deployment.
6. Automated Tuning: In some cases, automatically adjusting Spark configurations based on workload patterns and performance goals.
By leveraging such automated solutions, data teams can focus their expertise on building innovative data products while ensuring their Databricks environment remains optimized and cost-effective. Instead of spending hours digging through Spark UIs and log files, teams can quickly identify and resolve issues, or even prevent them from occurring in the first place.
Conclusion
Code optimization in Databricks is a multifaceted challenge that spans across SQL, Python, and Scala. While the problems are complex and the manual diagnosis and resolution process can be daunting, automated solutions offer a path to simplify and streamline these efforts. By leveraging such tools, organizations can more effectively manage their Databricks performance, improve job reliability, and allow their data teams to focus on delivering value rather than constantly battling optimization challenges.
Remember, whether you’re using manual methods or automated tools, optimization in Databricks is an ongoing process. As your data volumes grow and processing requirements evolve, staying on top of performance management will ensure that your Databricks implementation continues to deliver the insights and data products your business needs, efficiently and reliably.
To learn more about how Unravel can help with Databricks code optimization, request a health check report, view a self-guided product tour, or request a demo.