

Table of Contents
Mastercard is one of the world’s top payment processing platforms, with more than 700 million cards in use worldwide. In the US, nearly 40% of American adults hold a Mastercard-branded card. And the company is going from strength to strength; despite a dip in valuation of more than a third when the pandemic hit, the company has doubled in value three times in the last nine years, recently reaching a market capitalization of more than $350B dollars.
The importance of cards has soared as a result of the pandemic. Cash use has declined sharply as less purchasing is done in person, and even in-person shopping has shifted toward cards, for reasons of hygiene. For Mastercard, keeping their back-end machinery running well has been vital, both to maintain business results and for consumer and payment network confidence. Mastercard is a strong user of artificial intelligence, in particular for fraud reduction, and all sorts of reporting, business intelligence support, and advanced analytics are necessary to meet business needs and regulatory requirements.
At DataOps Unleashed, Mastercard’s Chinmay Sagade, Principal Engineer, and Srinivasa Gajula, Big Data Engineer, described a specific use of Unravel Data to increase platform resiliency. Mastercard uses Unravel to reject potentially harmful workloads on Hadoop, which improves job quality over time and keeps the platform available for all users.
Ad Hoc Query Loads vs. Hadoop, Impala, Spark, and Hive
“They were able to see the platform resiliency and availability improved.” – Chinmay Sagade
Mastercard relies primarily on Hadoop for core big data needs, having first adopted the platform ten years ago. Their largest cluster has hundreds of nodes, and they have petabytes of data. Thousands of users access the platform, with much usage being ad hoc. Impala and Spark are widely used, with some Hive usage in the mix.
There are several problems that are common in big data setups like the one in use at Mastercard – exacerbated, in this case, by the sheer scale at which Mastercard operates:
- These big data technologies are not easy for casual users to query correctly
- Poorly structured queries cause big system impacts
- Disks fill up, network pipes clog, and daemons are disabled, with unpredictable results
- Impacts include application failures, system slowdowns, system crashes, and resource bottlenecks
Before the pandemic, Mastercard’s big data stack was already at capacity. Rogue jobs were not only failing, but also affecting other jobs. One Hive query ran for 24 hours, pushing out other users. The need was strong to improve operational effectiveness, reduce resource utilization, and make room for growth, without additional infrastructure cost.
As Chinmay Sagade describes it, there is a “butterfly effect” – that is, “Big data means that even a small problem can cause a large impact.” He describes the situation as “a recipe for disaster,” as productivity plummets and SLAs are not met. He even cites receding hairlines as an occupational hazard for stressed Hadoop administrators.
Unravel Data (and Smart Operators) to the Rescue
“We saw an immediate positive impact on the platform.” – Chinmay Sagade
At Mastercard, the problems with query processing became so serious that user and management trust in the platform was in decline. A new solution to these problems was sorely needed.
Initial use of Unravel Data proved fruitful. For instance, Unravel Data identified that more than a third of data tables stored across technologies were unused. Removing these tables freed up resources. Repeating this scan now takes minutes, with actionable results, where it previously took days, and produced unreliable results.
Unravel Data is now used for several layers of defense against rogue queries:
- User and application owner self-tuning of their own query workloads
- Automated monitoring to alert on “toxic” workloads in progress
- Further monitoring to prevent the most hazardous workloads from running at all
Unravel helps improve resource usage, pre-empt many previous problems, and reduce mean time to remediation (MTTR) for the problems that remain.
Users who want to avoid problems can use Unravel Data to tune their own workloads. Their jobs then run faster, with far less chance of disruption, and they avoid automated alerts or even workload shutdowns.
Take the Unravel tour

But users can be in a hurry. They may not know how to check their own workloads, or they may make mistakes despite the availability of checking. The Mastercard data team needed another layer of defense.
Using Runtime Data to Manage Outliers
“We will ask them to take the necessary actions, like tuning the quarry and resubmitting again.” – Srinivasa Gajula
Mastercard took additional steps to monitor and act on toxic workloads. They created a Python-based framework which collects application data at runtime. Anomaly detection algorithms scan relevant metrics and flag toxic workloads. All of this connects to Unravel.
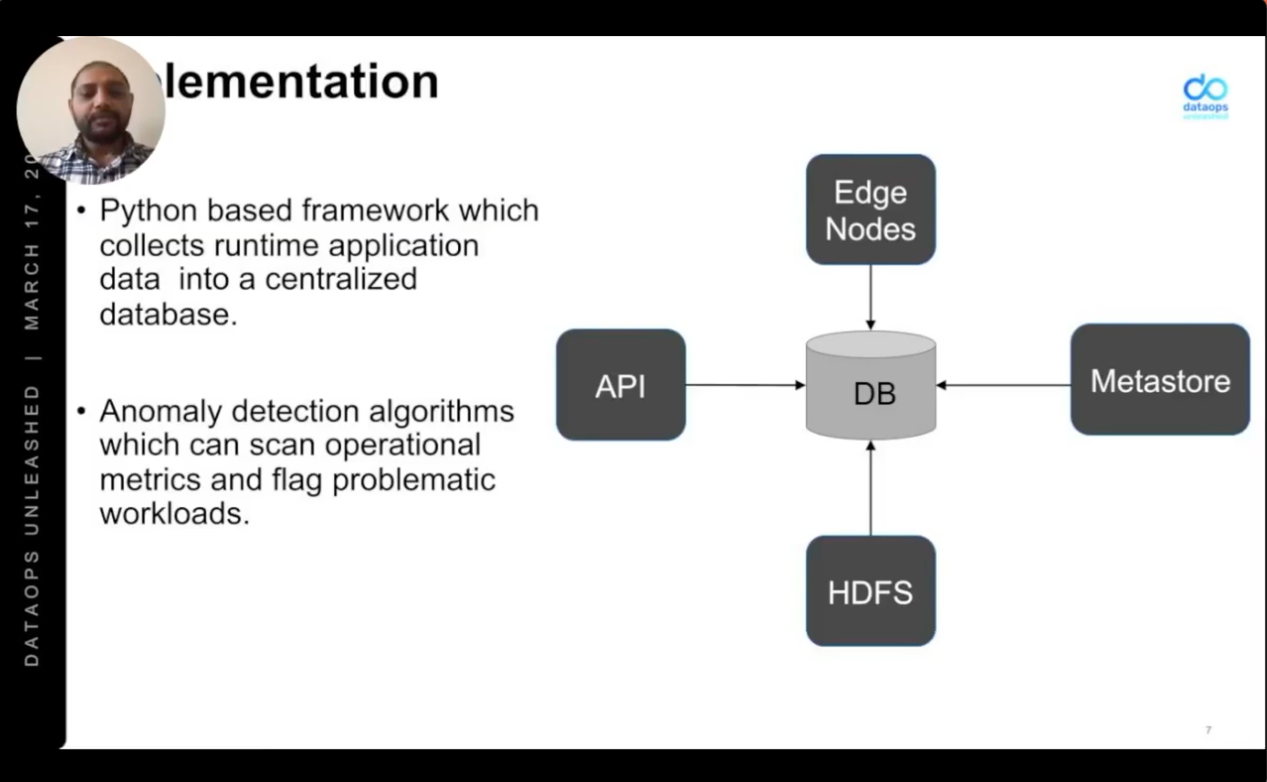
“We use the Impala and Yarn APIs to collect metrics, along with HDFS metadata,” says Srinivasa Gajula. They produce summary reports to note the number and percentage of workloads that fail with out-of-memory errors, syntax errors, and other causes. They detect excessive numbers of small files and calculate both mean time between failures (MTBF) and mean time to repair (MTTR). This information is shared with users and application owners, helping them to make proper use of the platform.
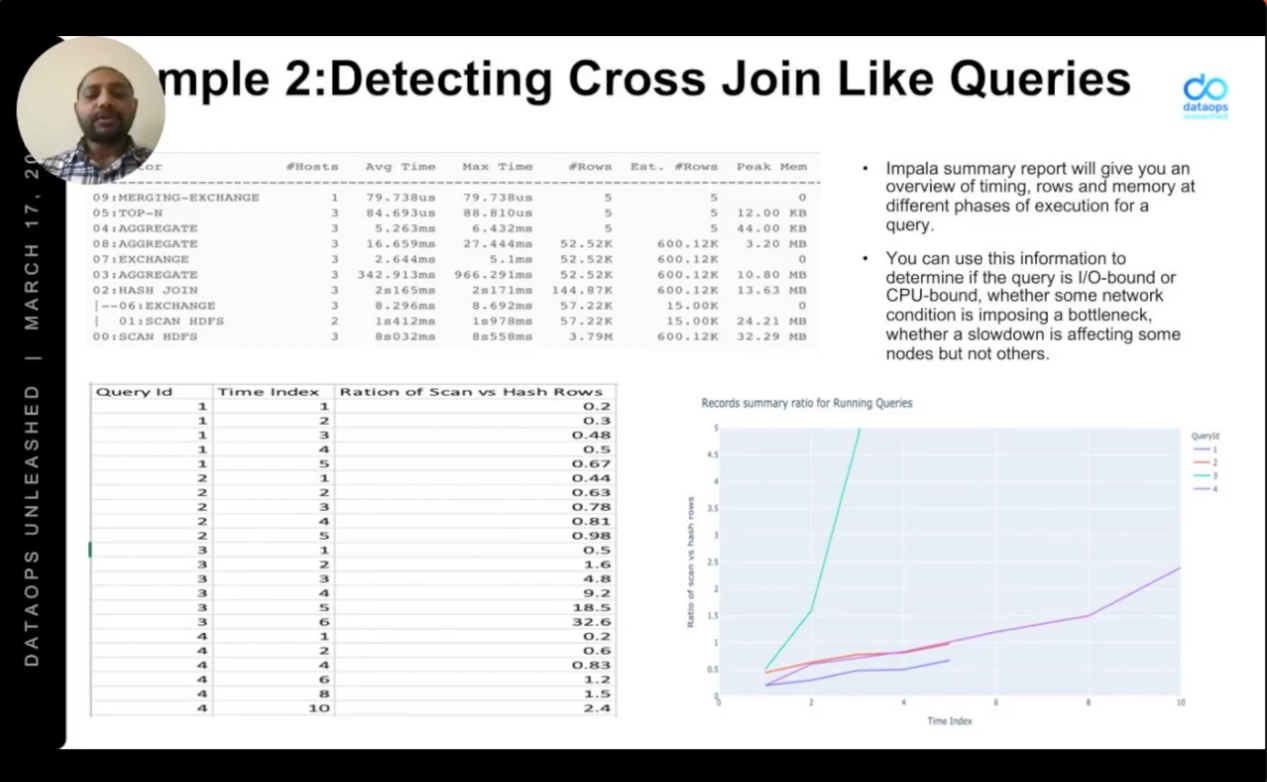
They also detect different types of joins and identify, as the join proceeds, whether it’s likely to make excessive demands on the system. When a user provides compute stats to Impala, for instance, then Impala can identify whether specific tables should be broadcasted, or shuffled, and how to filter data for optimal performance. And users can provide hints in the query to, for example, broadcast a small table, or shuffle a larger one.
But many users run their queries without providing this helpful information. Impala may then broadcast a large table, for example, causing a performance slowdown or even a crash.
So Mastercard now identifies these issues as they begin to occur. They build a tree from operator dependencies and predict whether a large table, for instance, is likely to be broadcast. If so, the user is asked to tune the query, and submit it again.
They can even identify whether a particular query is CPU-bound or I/O bound. Where a cross join, for instance, is causing the number of rows produced to grow exponentially, in a way that is likely to cause performance issues, or even stability problems for the platform. They can alert the user or, in extreme cases, kill the query.
Unravel is now part of the software development life cycle (SDLC) process at Mastercard. Application quality increases up front, and the ability to fix remaining problems in production is greatly improved as well.
Get answers, not more charts and graphs
Business Impacts of Pre-Checking and Pre-Emption
“Now administrators can spend their time in value-added activities.” – Chinmay Sagade
Mastercard has racked up many benefits by empowering users to check their own queries and pre-empting the remainder that are not “fixed” and are still problematic:
- Less time spent troubleshooting
- Greater reliability
- Resources not over-allocated, so resources are freed up
- Infrastructure costs reduced through appropriate use or resources

Not all of this has been easy. Users needed plenty of notice and detailed documentation. And they can only be expected to learn so much about how to right-size their own queries. But users have actually supported restrictions on unbalanced jobs, as they see the benefits of better query performance and a more reliable platform for everyone.
This blog post is a good starting point, but it’s worth taking the time to watch the Mastercard presentation yourself. And you can view all the videos from DataOps Unleashed here. You can also download The Unravel Guide to DataOps, which was made available for the first time during the conference.