CLOUD MIGRATION ASSESSMENT AND RECOMMENDATIONS AS YOU PLAN TO MIGRATE DATA WORKLOADS TO CLOUD
Smooth your path to the cloud with Unravel cloud migration assessment, guidance, and automation.
** DO NOT REMOVE Hidden Margin Required **
** DO NOT REMOVE Hidden Margin Required **
Unravel for your cloud migration strategy
Does it make financial sense to migrate your Hadoop and Spark apps running on Cloudera or MapR to the cloud? Do you have the data and insights to know for sure?
Whether you are considering a cloud migration to Microsoft Azure, AWS or GCP Unravel provides the intelligence and visibility with our best-in-class cloud migration assessment that answers key questions while reducing the cost and effort of your cloud migration.
** DO NOT REMOVE Hidden Margin Required **
Plan for success with predictive analytics
Look before you leap into the cloud – make the right choice for your cloud migration strategy with AI-driven insights and assessments.
** DO NOT REMOVE Hidden Margin Required **
** DO NOT REMOVE Hidden Margin Required **
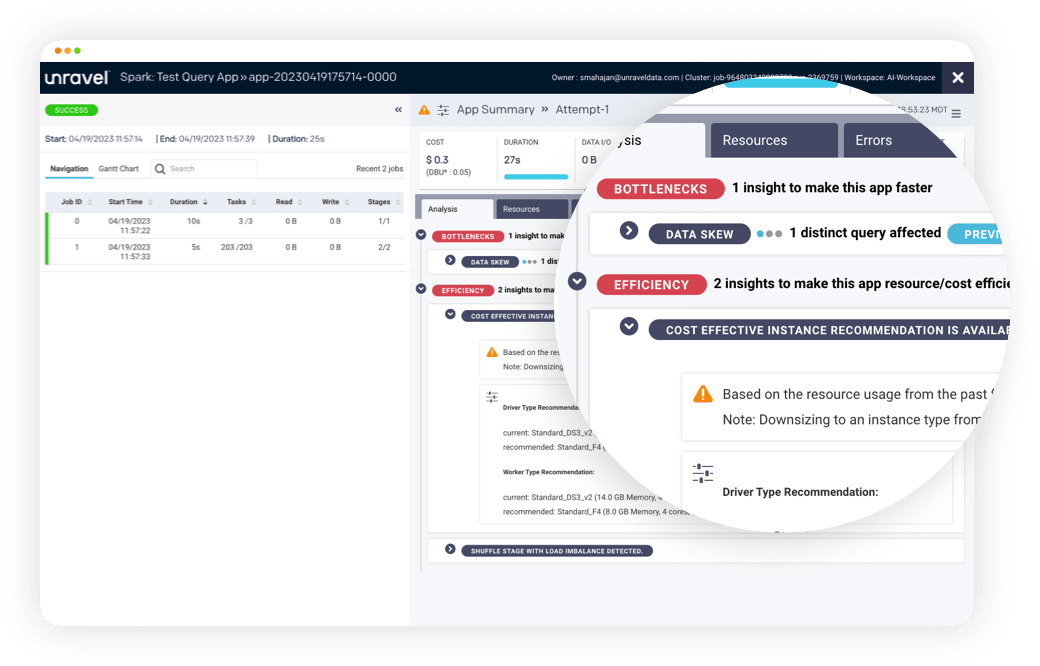
As you’re migrating your Spark and Hadoop applications to the cloud, Unravel helps ensure you won’t be flying blind.
With data-driven intelligence and recommendations for optimizing compute, memory, and storage resources, Unravel makes your transition a smooth one. Among our capabilities in this area Unravel:
Provides intelligence for migrating Cloudera, Hortonworks, and MapR Hadoop and Spark implementations to AWS IaaS/EMR/Databricks, Microsoft Azure IaaS/HDInsight/Azure Databricks and GCP IaaS/Dataproc.
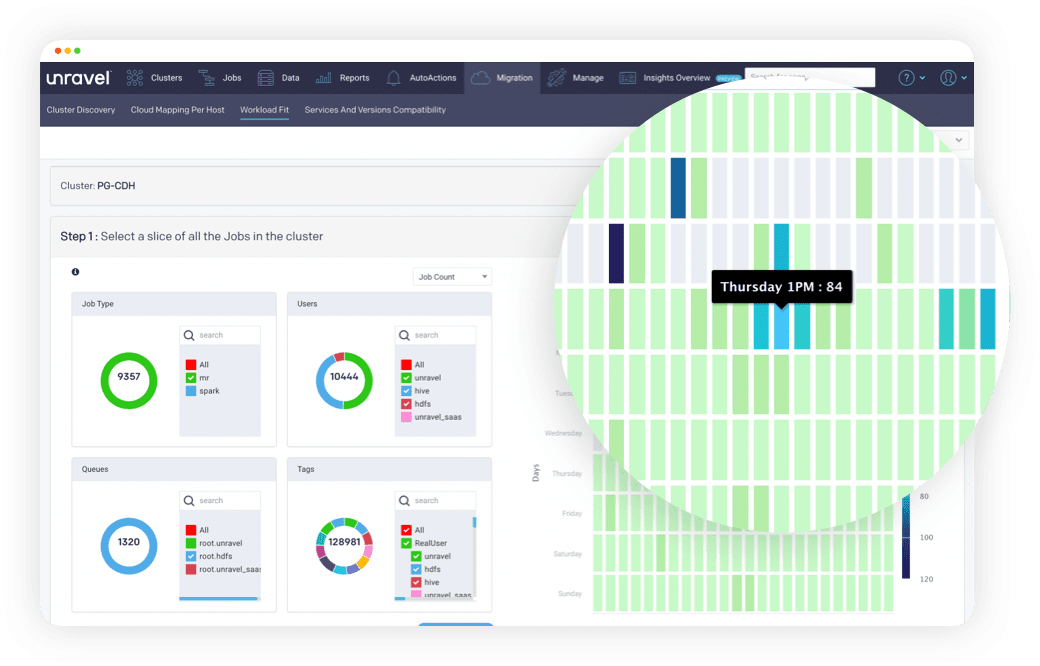
Provides detailed dependency maps to help you understand resource requirements before you migrate.
Reveals the seasonality and ideal time of day to take advantage of the best prices for cloud services, spot instances, autoscaling, and more.
Reduces cloud costs by enabling automatic app speedup, optimized resource usage, and intelligent data tiering.
** DO NOT REMOVE Hidden Margin Required **
Slice and dice application workloads to ensure effective cloud migration
Ensure the best possible transition to the cloud with insights and guidance before, during, and after migration.
** DO NOT REMOVE Hidden Margin Required **
** DO NOT REMOVE Hidden Margin Required **
Unravel provides a deeper level of insight into your cloud migration.
Unravel reveals the relative success and cost of your move to the cloud and offers actionable recommendations for improving these metrics. To increase your odds for a successful migration, use Unravel to:
Validate your decision to migrate by baselining performance before and after the move.
Compare how apps perform before and after the transition – and optimizing them for the new cloud runtime environment.
Offer guidance to improve the performance, scalability, and reliability of your apps once they’re in the cloud.
** DO NOT REMOVE Hidden Margin Required **
Post-migration cost accounting, chargeback and optimization
Objective proof of success: get the insight you need to demonstrate and increase your return on investment.
** DO NOT REMOVE Hidden Margin Required **
** DO NOT REMOVE Hidden Margin Required **
Unravel helps quantify the success of your migration
Make the benefits tangible to your business – by providing the hard facts, clear metrics, and informed forecasting you need. Unravel also continually delivers new intelligence and recommendations to keep delivering consistent, cost-effective performance for the long haul.
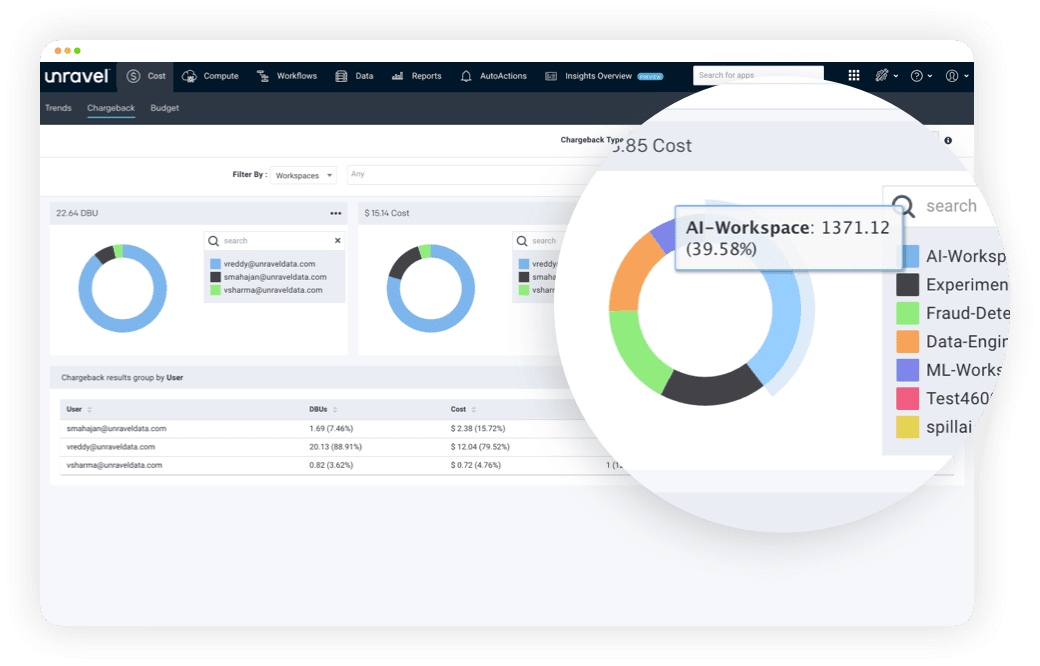
Identify which users, applications, and projects are having the biggest impact, with chargeback and showback capabilities.
Break down costs by CPU, memory, I/O, and storage – and get recommendations for potential savings.
Automatically detect and mitigate the inefficient use of resources by application – including CPU, memory, containers, caching, and nodes.