

Table of Contents
Identifying issues in distributed applications like a Spark streaming application is not trivial. This blog describes how Unravel helps you connect the dots across streaming applications to identify bottlenecks.
Spark streaming is widely used in real-time data processing, especially with Apache Kafka. A typical scenario involves a Kafka producer application writing to a Kafka topic. The Spark application then subscribes to the topic and consumes records. The records might be further processed downstream using operations like map and foreachRDD ops or saved into a datastore.
Below are two scenarios illustrating how you can use Unravel’s APMs to inspect, understand, correlate, and finally debug issues around a Spark streaming app consuming a Kafka topic. They demonstrate how Unravel’s APMs can help you perform an end-to-end analysis of the data pipelines and its applications. In turn, this wealth of information helps you effectively and efficiently debug and resolve issues that otherwise would require more time and effort.
Use Case 1: Producer Failure
Consider a running Spark application that has not processed any data for a significant amount of time. The application’s previous iterations successfully processed data and you know for a certainty that current iteration should be processing data.
Detect Spark is processing no data
When you notice the Spark application has been running without processing any data, you want to check the application’s I/O.
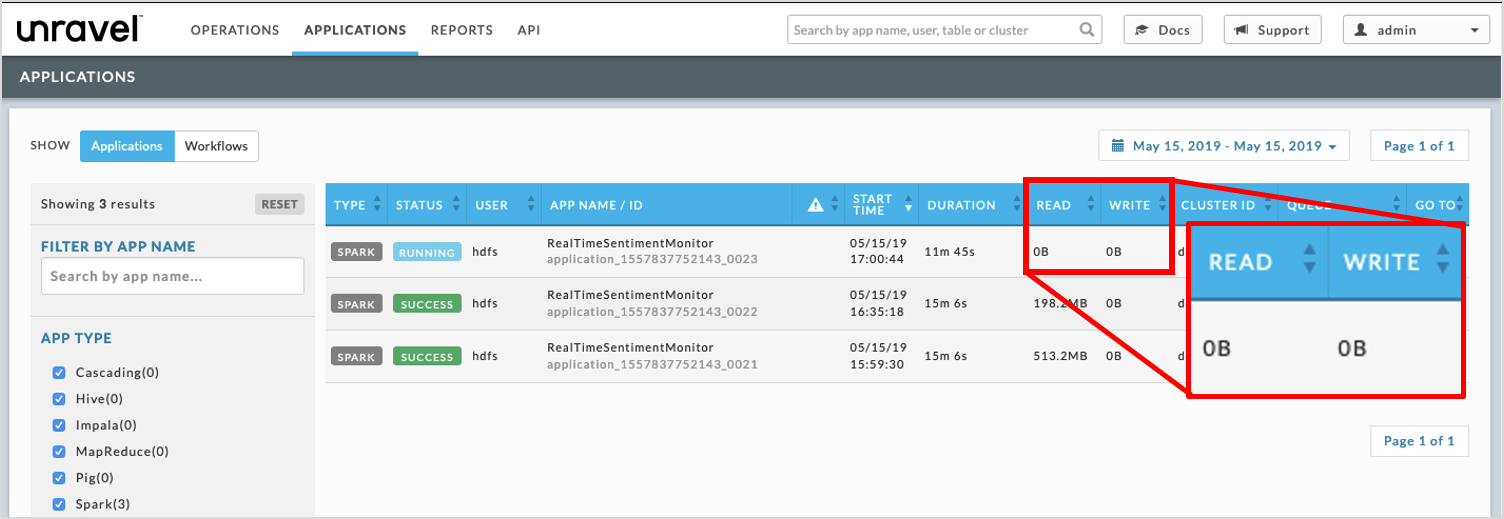
Checking I/O Consumption
Click on it to bring up the application and see its I/O KPI
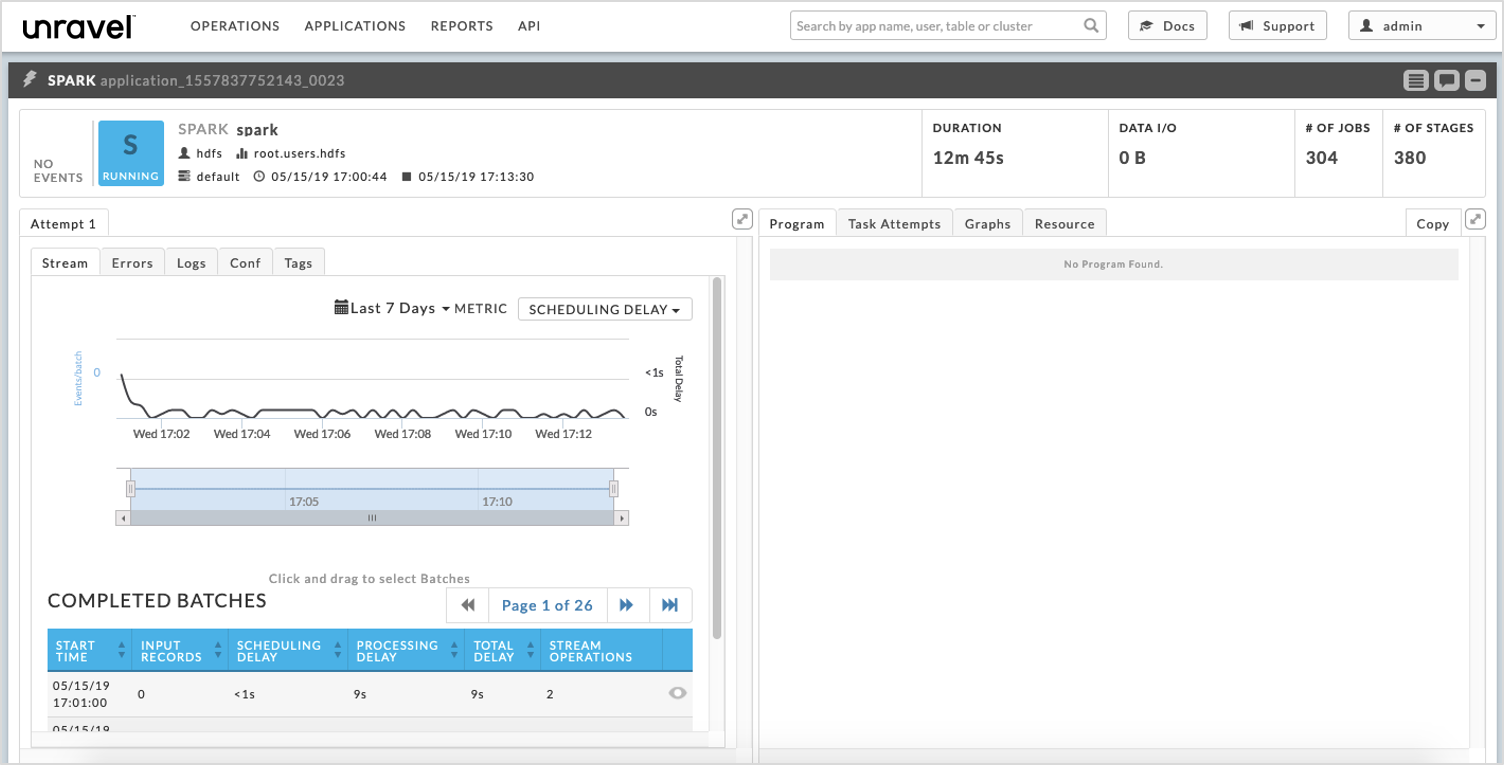
View Spark input details
When you see the Spark application is consuming from Kafka, you need to examine Kafka side of the process to determine the issue. Click on a batch to find the topic it is consuming.
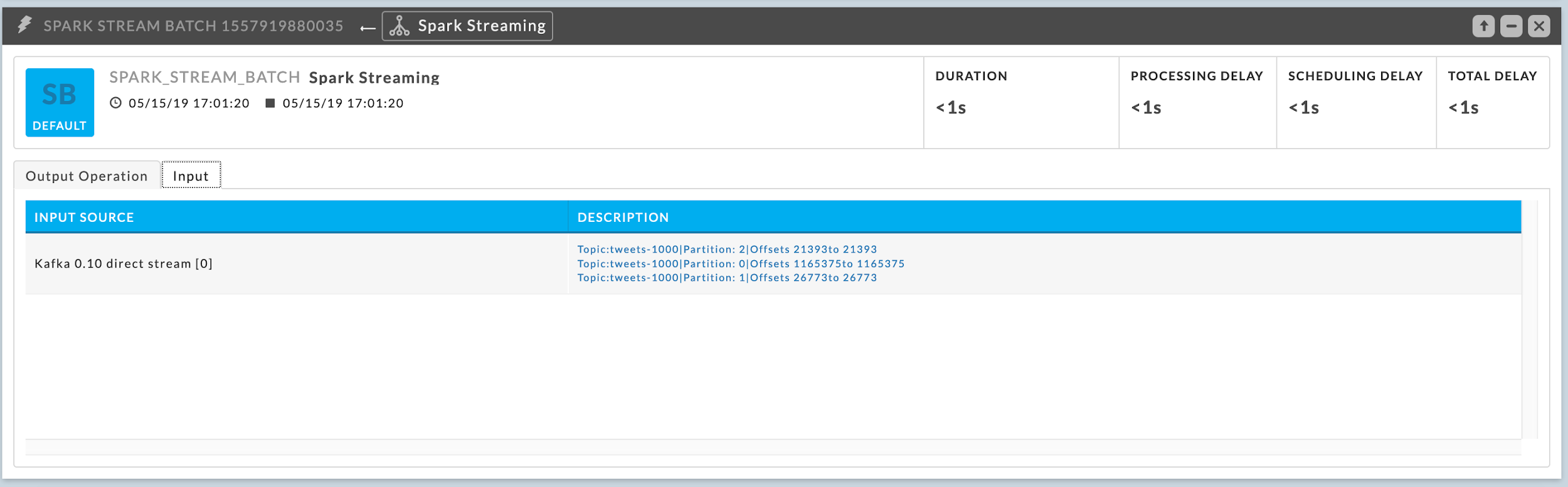
View Kafka topic details
Bring up the Kafka Topic details which graphs the Bytes In Per Second, Bytes Out Per Second, Messages In Per Second, and Total Fetch Requests Per Second. In this case, you see Bytes In Per Second and Messages In Per Second graphs show a steep decline; this indicates the Kafka Topic is no longer producing any data.
The Spark application is not consuming data because there is no data in the pipeline to consume.
You should notify the owner of the application that writes to this particular topic. Upon notification, they can drill down to determine and then resolve the underlying issues causing that writes to this topic to fail.
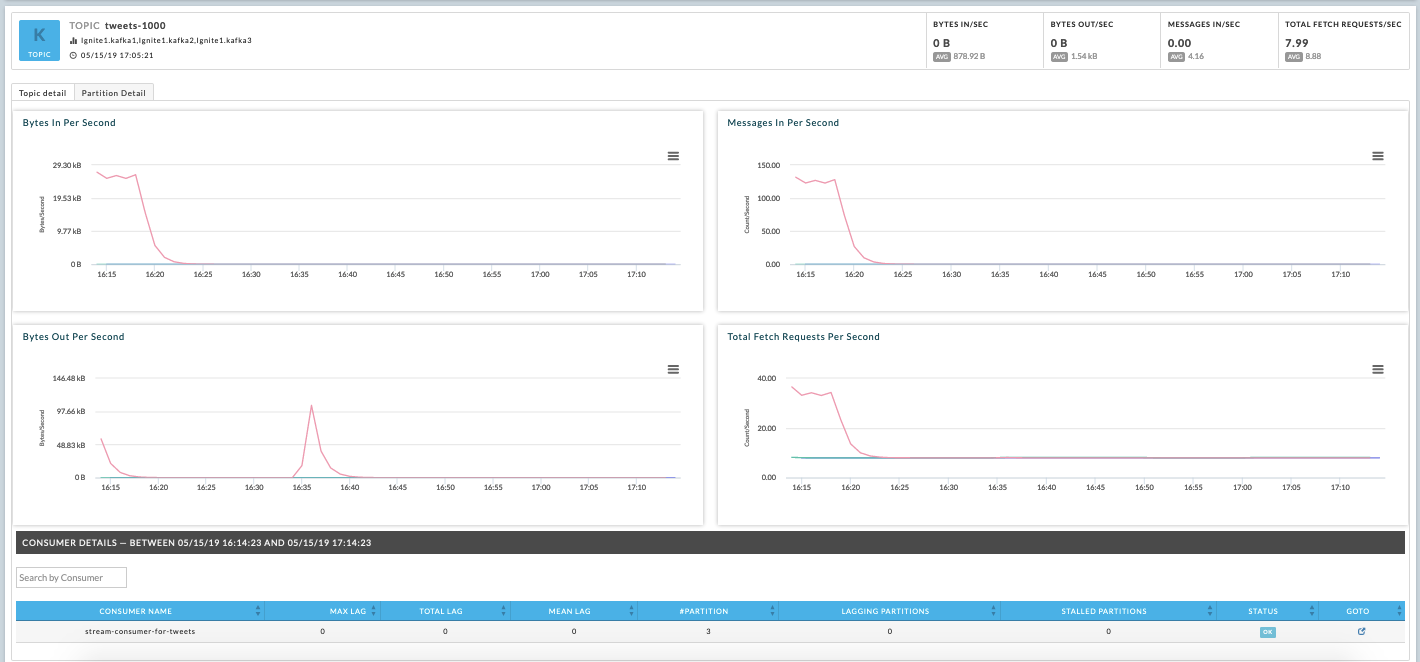
The graphs show a steep decline in the BytesInPerSecond and MessagesInPerSecond metric. Since there is nothing flowing into the topic, there is no data to be consumed and processed by Spark down the pipeline. The administrator can then alert the owner of the Kafka Producer Application to further drill down into what are the underlying issues that might have caused the Kafka Producer to fail.
Use Case 2: Slow Spark app, offline Kafka partitions
In this scenario, an application’s run has processed significantly less data when compared to what is the expected norm. In the above scenario, the analysis was fairly straightforward. In these types of cases, the underlying root cause might be far more subtle to identify. The Unravel APM can help you to quickly and efficiently root cause such issues.
Detect inconsistent performance
When you see a considerable difference in the data processed by consecutive runs of a Spark App, bring up the APMs for each application.
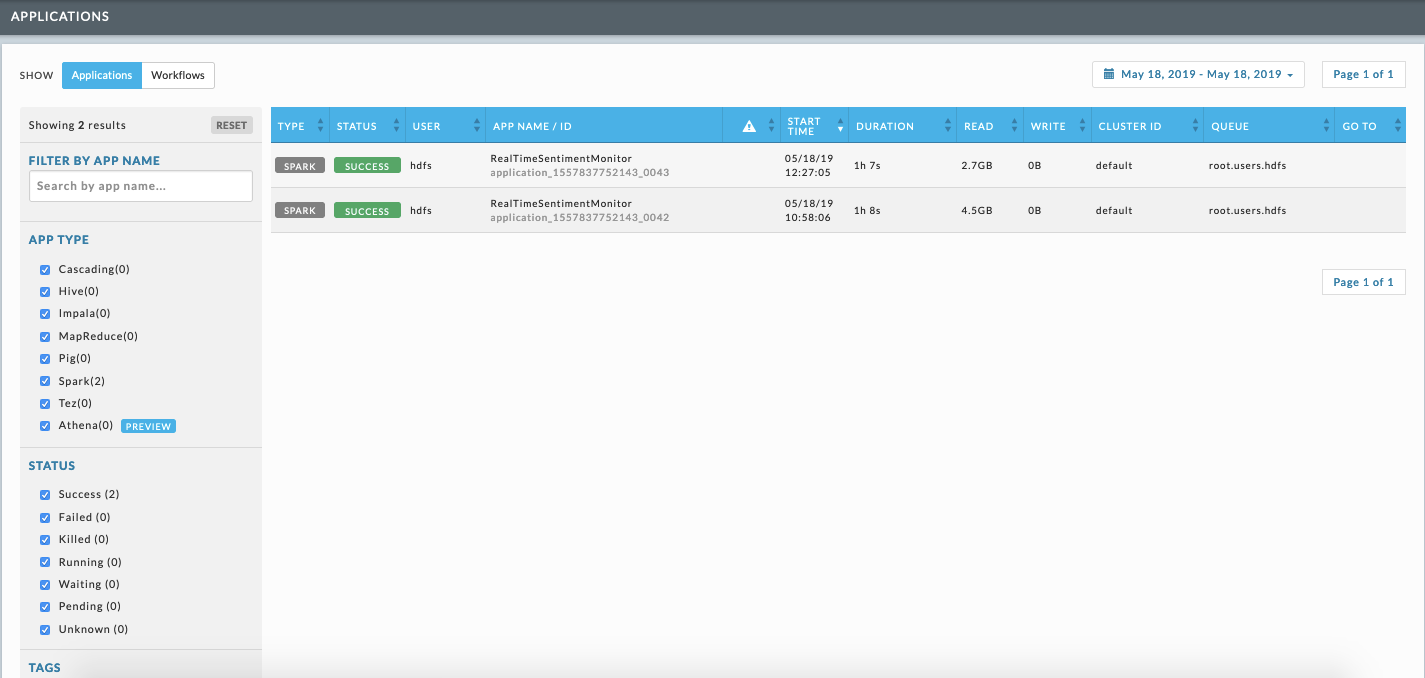
Detect drop in input records
Examine the trend lines to identify a time window when there is a drop in input records for the slow app. The image, the slow app, shows a drop off in consumption.
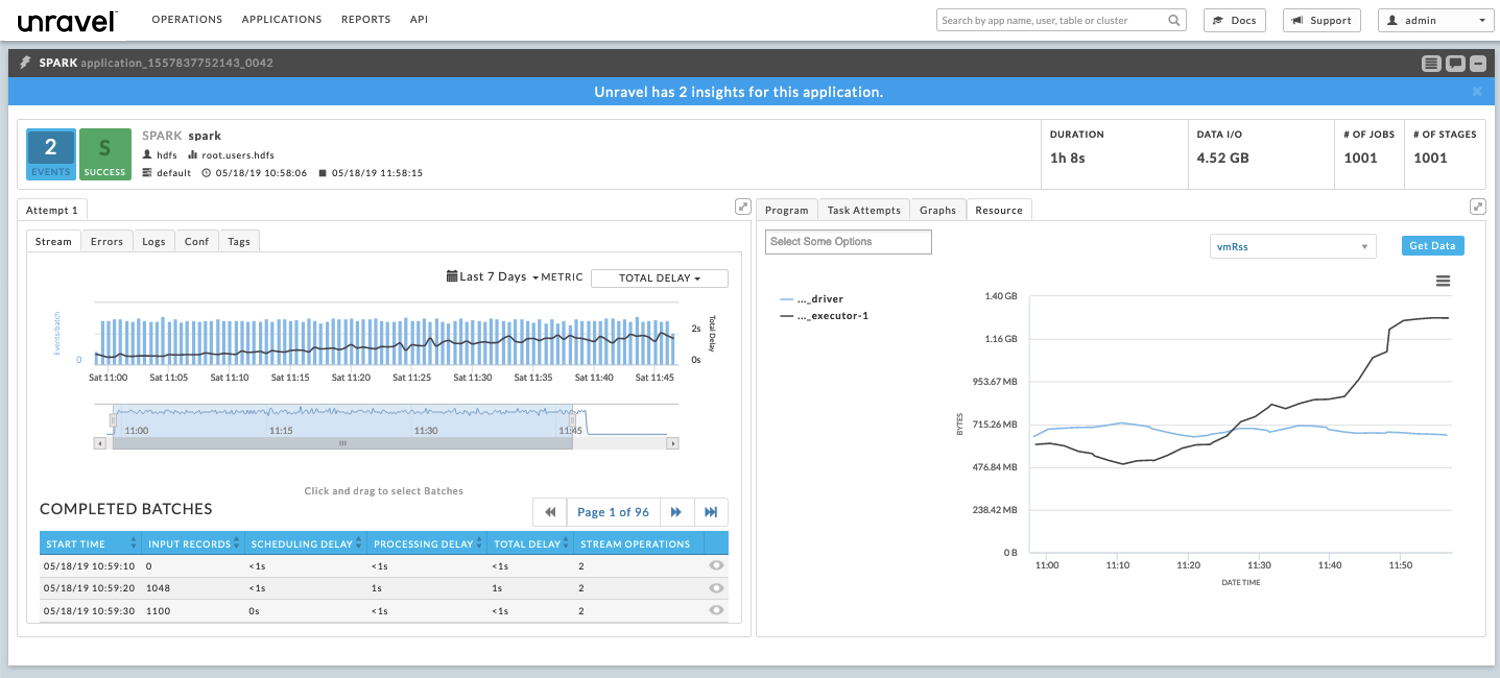
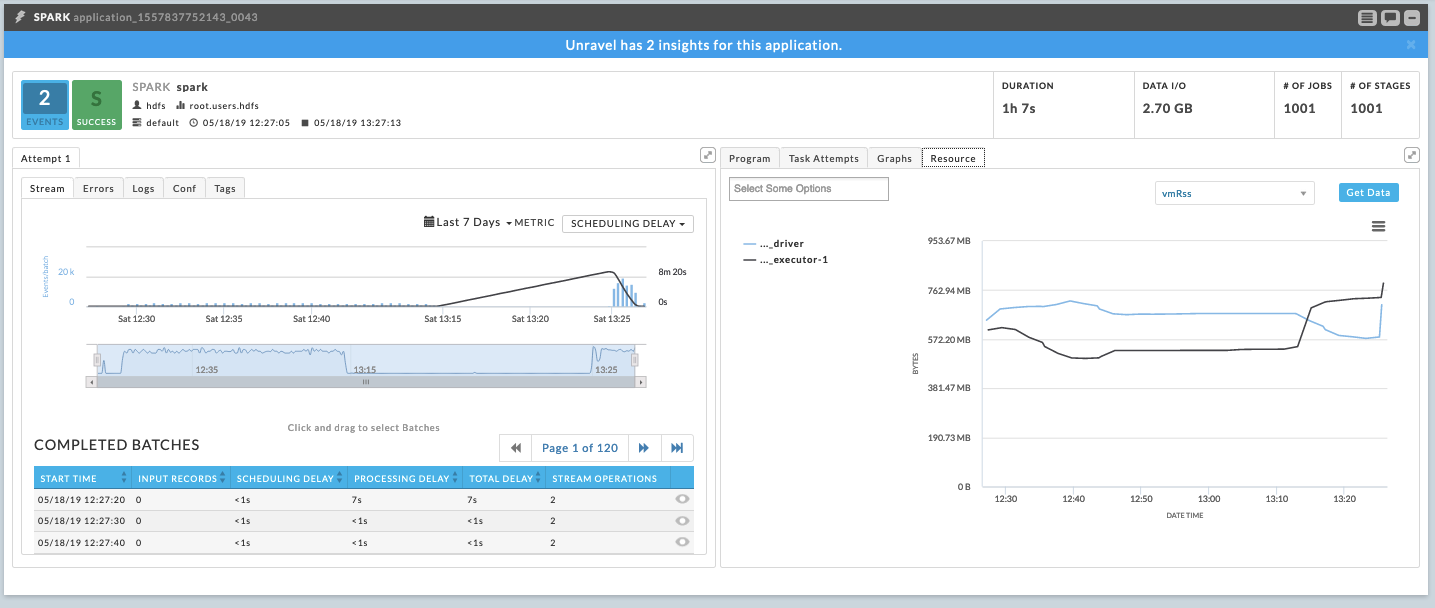
Drill down to I/O drop off
Drill down into the slow application’s stream graph to narrow the time period (window) in which the I/O dropped off.
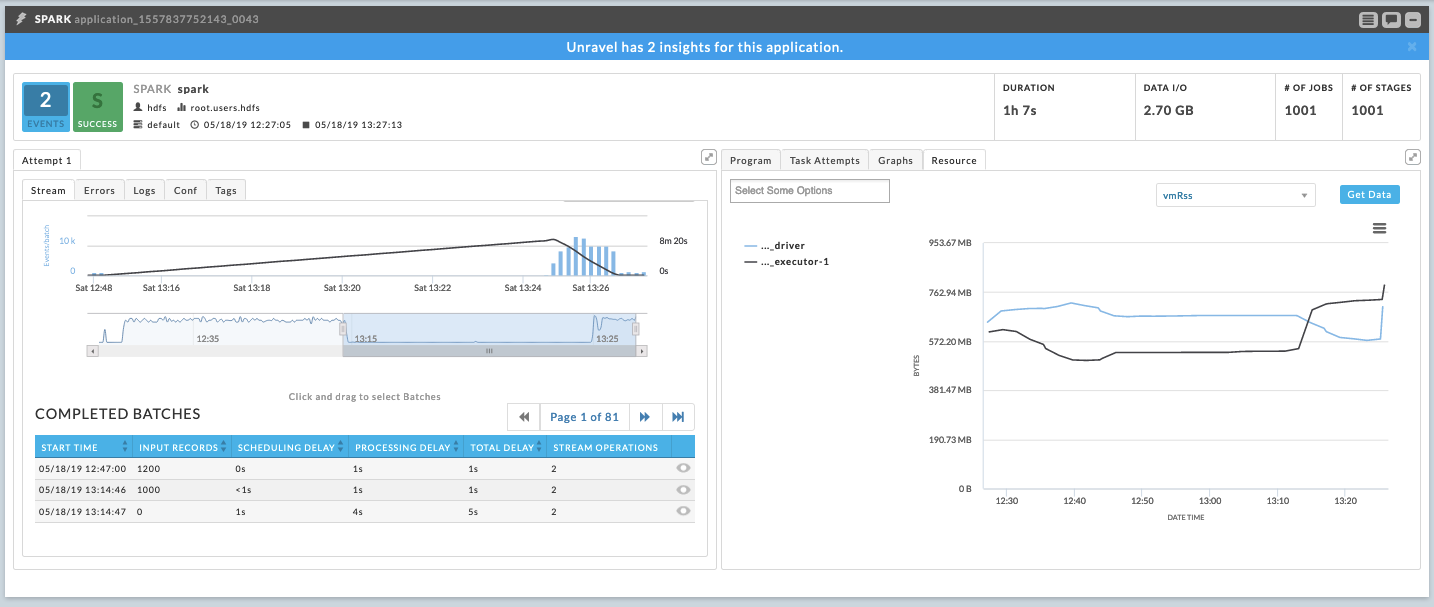
Drill down to suspect time interval
Unravel displays the batches that were running during the problematic time period. Inspect the time interval to see the batches’ activity. In this example no input records were processed during the suspect interval. You can dig further into the issue by selecting a batch and examining it’s input tab. In the below case, you can infer that no new offsets have been read based upon the input source’s description,“Offsets 1343963 to Offset 1343963”.
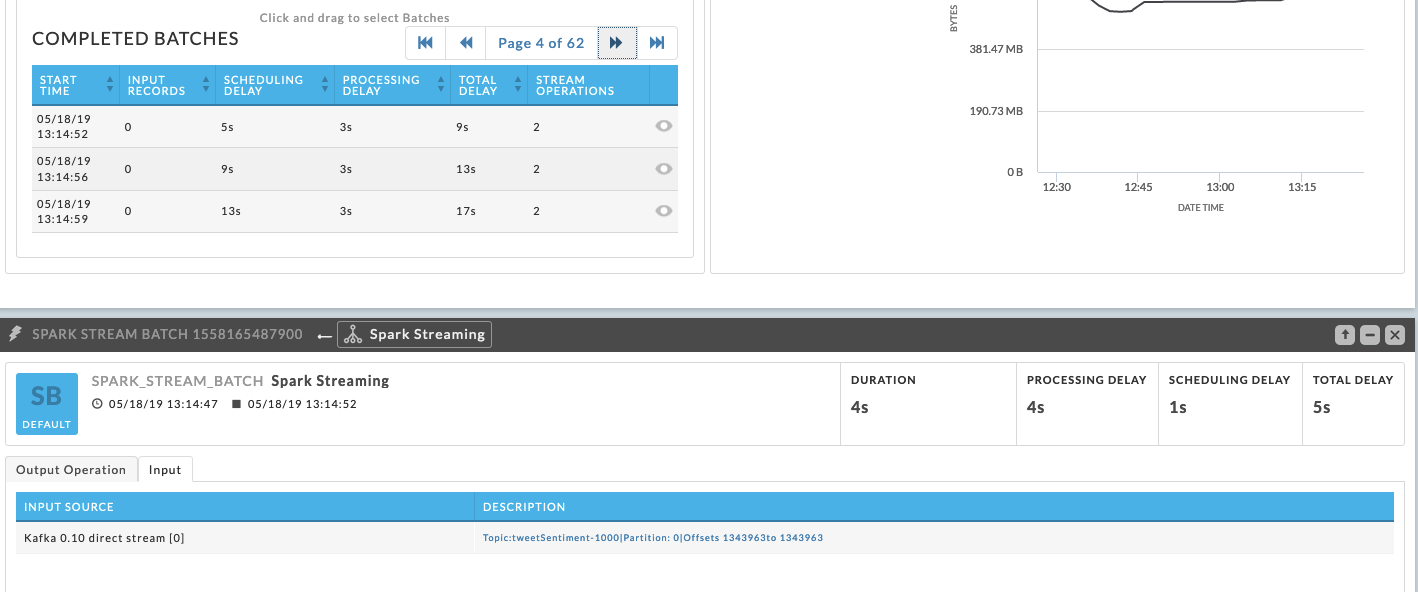
View KPIs on the Kafka monitor screen
You can further debug the problem on the Kafka side by viewing the Kafka cluster monitor. Navigate to OPERATIONS > USAGE DETAILS > KAFKA. At a glance, the cluster’s KPIs convey important and pertinent information.
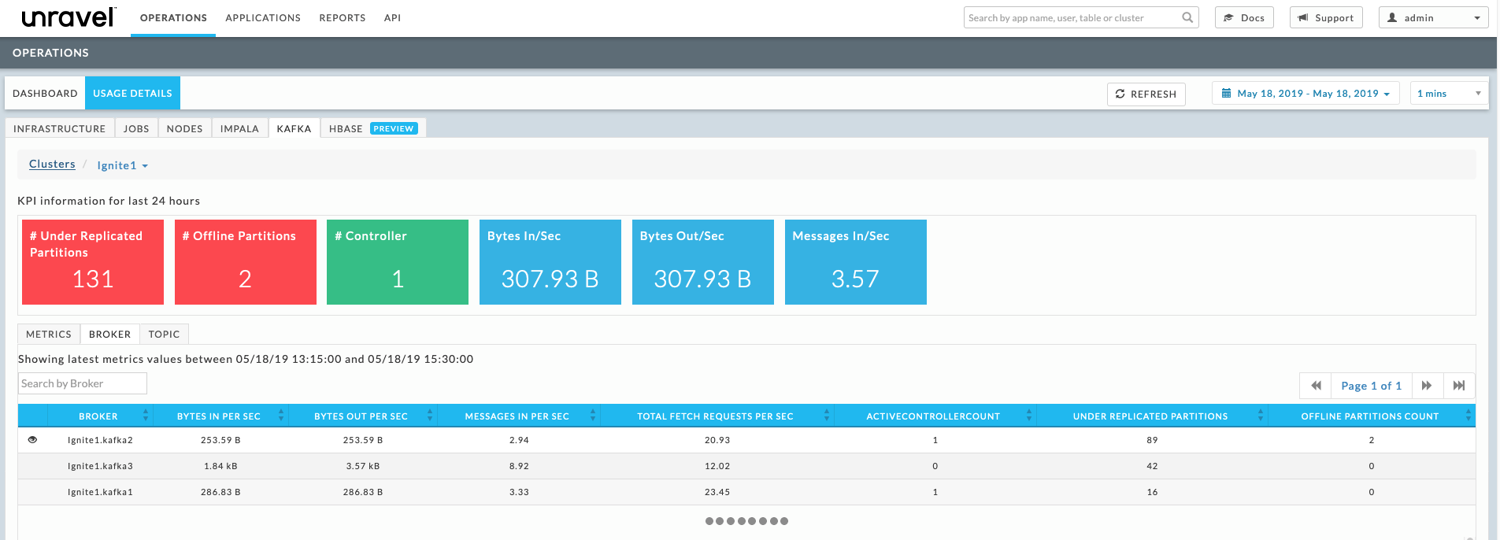
Here, the first two metrics show that the cluster is facing issues which need to be resolved as quickly as possible.
# of under replicated partitions is a broker level metric of the count of partitions for which the broker is the leader replica and the follower replicas that have yet not caught up. In this case there are 131 under replicated partitions.
# of offline partitions is a broker level metric provided by the cluster’s controlling broker. It is a count of the partitions that currently have no leader. Such partitions are not available for producing/consumption. In this case there are two (2) offline partitions.
You can select the BROKER tab to see broker table. Here the table hints that the broker, Ignite1.kafka2 is facing some issue; therefore, the broker’s status should be checked.
- Broker Ignite1.kafka2 has two (2) offline partitions. The broker table shows that it is/was the controller for the cluster. We could have inferred this because only the controller can have offline partitions. Examining the table further, we see that Ignite.kafka1 also has an active controller of one (1).
- The Kafka KPI # of Controller lists the Active Controller as one (1) which should indicate a healthy cluster. The fact that there are two (2) brokers listed as being one (1) active controller indicates the cluster is in an inconsistent state.
Identify cluster controller
In the broker tab table, we see that for the broker Ignite1.kafka2 there are two offline Kafka partitions. Also we see that the Active controller count is 1, which indicates that this broker was/is the controller for the cluster (This information can also be deduced from the fact that offline partition is a metric exclusive only to the controller broker). Also notice that the controller count for Ignite.kafka1 is also 1, which would indicate that the cluster itself is in an inconsistent state.
This gives us a hint that it could be the case that the Ignite1.kafka2 broker is facing some issues, and the first thing to check would be the status of the broker.
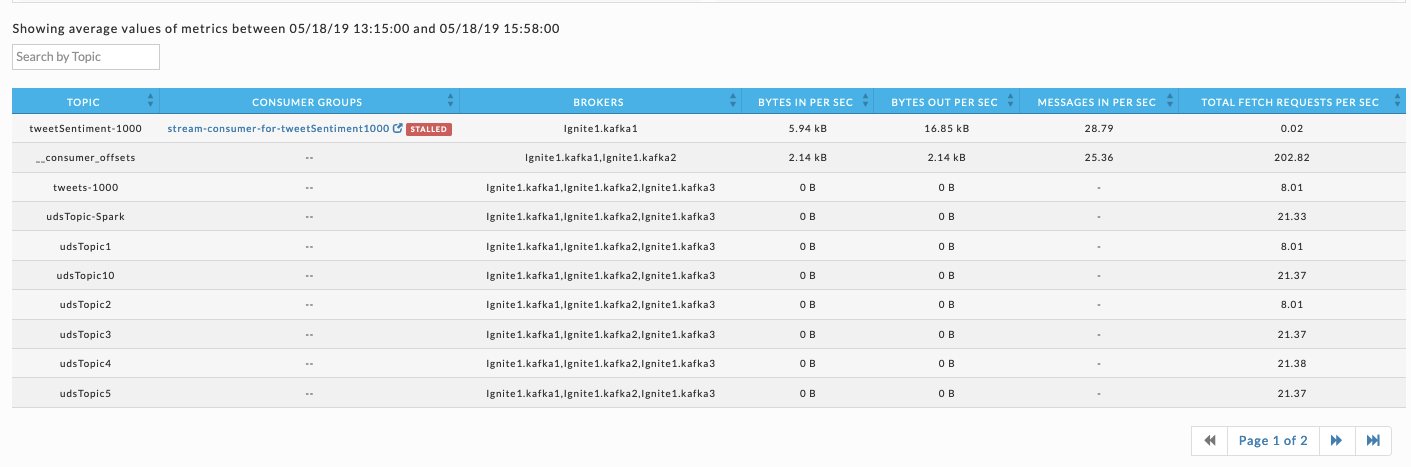
View consumer group status
You can further corroborate the hypothesis by checking the status of the consumer group for the Kafka topic the Spark App is consuming from. In this example, consumer groups’ status indicates it’s currently stalled. The topic the stalled group is consuming is tweetSentiment-1000.
 Topic drill down
Topic drill down
To drill down into the consumer groups topic, click on the TOPIC tab in the Kafka Cluster manager and search for the topic. In this case, the topic’s trend lines for the time range the Spark applications consumption dropped off show a sharp decrease in the Bytes In Per Second and Bytes Out Per Second. This decrease explains why the Spark app is not processing any records.
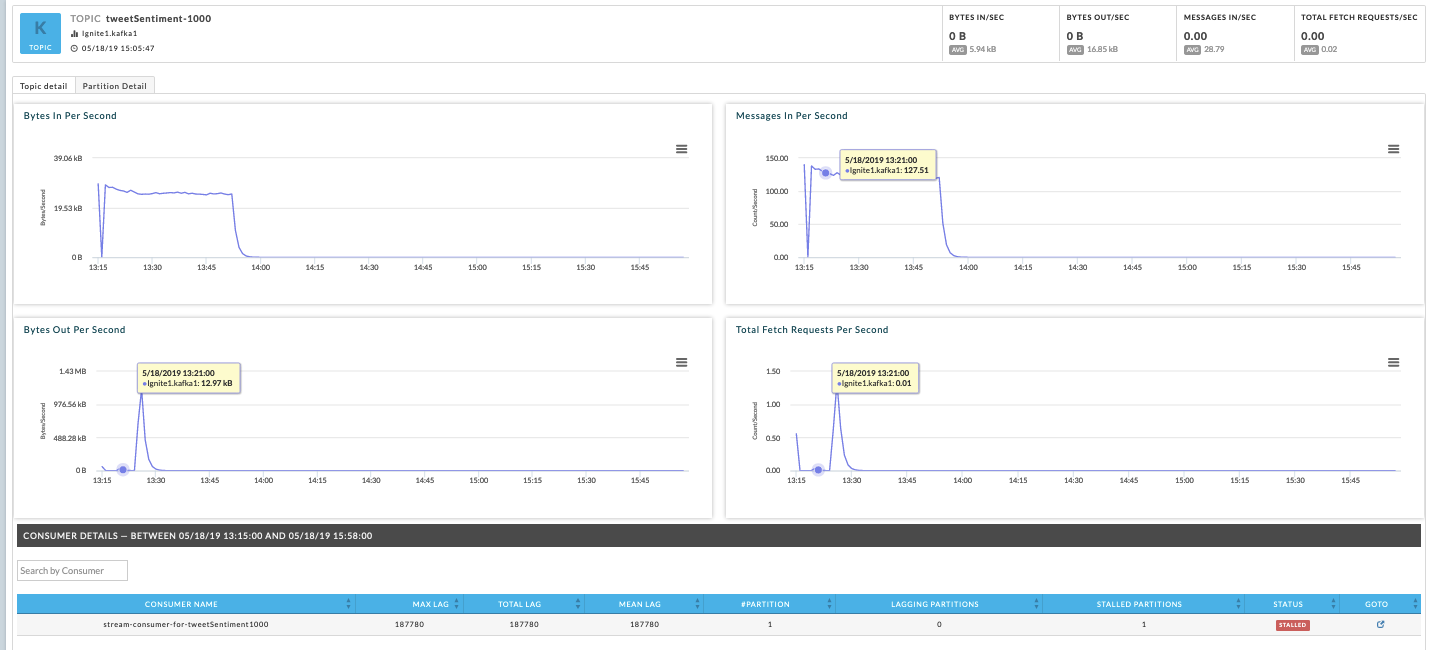
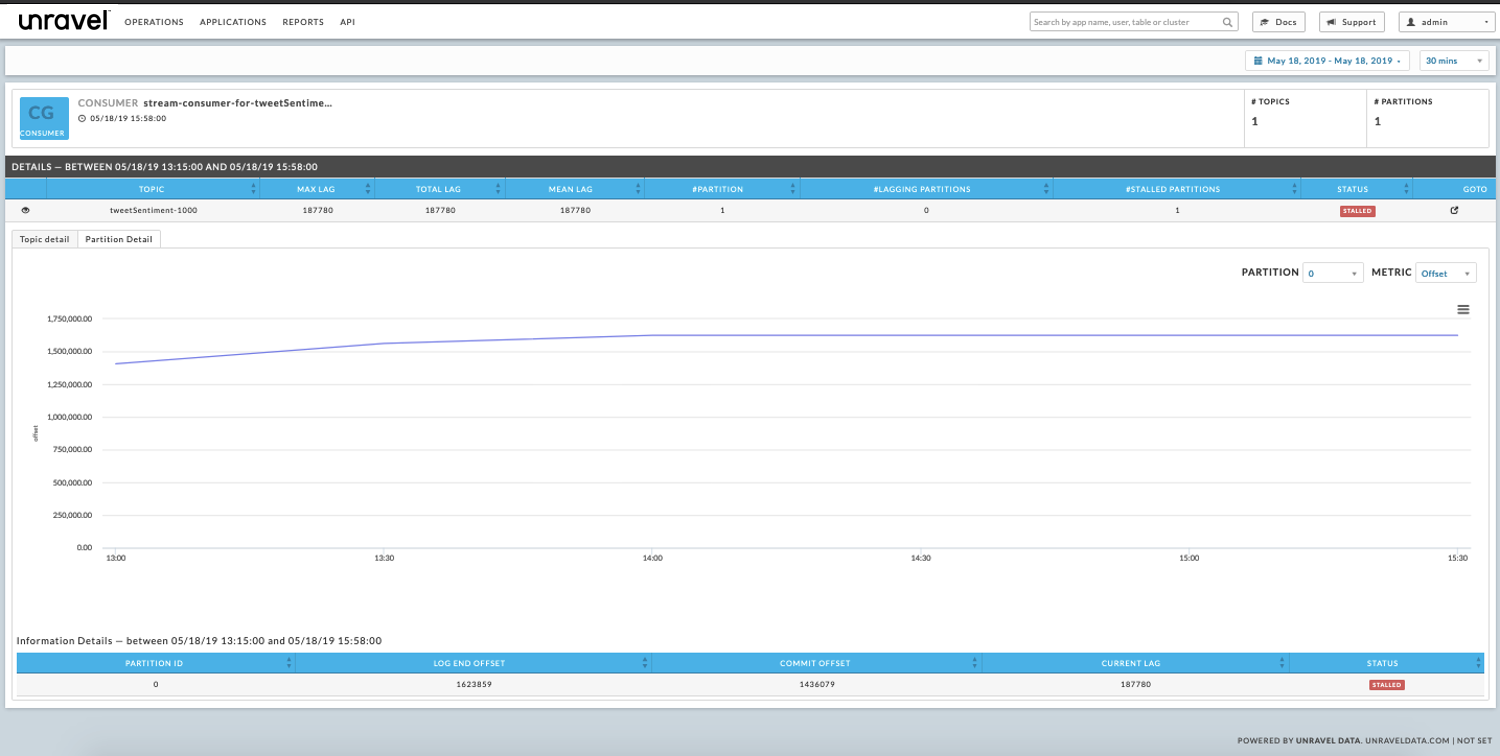
Consumer group details
To view the consumer groups lag and offset consumption trends, click on the consumer groups listed for the topic. Below, the topic’s consumer groups, stream-consumer-for-tweetSentimet1000, log end offset trend line is a constant (flat) line that shows no new offsets have been consumed with the passage of time. This further supports our hypothesis that something is wrong with the Kafka cluster and especially broker Ignite.kafka2.
Conclusion
These are but two examples of how Unravel helps you to identify, analyze, and debug Spark Streaming applications consuming from Kafka topics. Unravel’s APMs collates, consolidates, and correlates information from various stages in the data pipeline (Spark and Kafka), thereby allowing you to troubleshoot applications without ever having to leave Unravel.