

Table of Contents
Current trends indicate that the cloud is a boon for big data. Conversations with our customers also clearly indicate this trend of data workloads and pipelines moving to the cloud. More and more organizations across industries are running – or are looking to run – data pipelines, machine learning, and AI in the cloud. And until today, there has not been an easy way to migrate, deploy and manage data-driven applications in the cloud. But now, getting the most from modern data applications in the cloud requires data driven planning and execution.
Unravel provides full-stack visibility and AI-powered guidance to help customers understand and optimize the performance of their data-driven applications and monitor, manage and optimize their modern data stacks. This applies as much to clusters located in the cloud as it does to modern data clusters on-premise. Specifically, for the cloud, our goal is to cover the entire gamut below:
- IaaS (Infrastructure as a Service): Cloudera, Hortonworks or MapR data platforms deployed on cloud VMs where your modern data applications are running
- PaaS (Platform as a Service): Managed Hadoop/Spark Platforms like AWS Elastic MapReduce (EMR), Azure HDInsight, Google Cloud Dataproc etc.
- Cloud-Native: Products like Amazon Redshift, Azure Databricks, AWS Databricks etc.
- Serverless: Ready to use, no setup needed services like Amazon Athena, Google BigQuery, Google Cloud DataFlow etc.
We have also learnt that enterprises tend to use a combination of one or more of the above to solve their modern data stack needs. In addition, it is not uncommon to have more than one cloud provider in use (Multi-Cloud Strategy). Often workloads and data are also distributed between on-premise and cloud clusters (Hybrid Strategy).
This blog covers Unravel’s current capabilities in the cloud, what is currently in the works, and what is on our longer term roadmap. Most importantly we talk about how you can participate and be part of this wave with us!
Looking to Migrate your Modern Data Workloads to the Cloud?
Many enterprises today are looking to migrate their modern data workloads from on-premises to the Cloud. The goals vary from improving ease of management to increasing elasticity to assure SLAs for bursty workloads to reducing costs.
Unravel truly understands your modern data cluster, details of the workloads running on that (and what can be done for improving reliability, efficiency and time to root cause issues). Now, this information and analysis are key for initiatives like migrating your modern data workloads to the cloud as well. So, Unravel has done precisely this – providing you features to help plan and migrate your modern data stack applications to the cloud based on your specific goal(s) (e.g. cost reduction, increased SLA, agility etc.). We have built a Goal-Driven and Adaptive Solution for helping Migrating Modern Data Stack Applications to the Cloud.
Pre-Migration: Planning
Cluster Discovery
Migrating modern data stack workloads to the cloud requires extensive planning, which in turn begins with developing a really good understanding the current (on-premise) environment. Specifically, details around cluster resources and their usage.
Cluster Details
What’s my modern data stack cluster like? What are the services deployed? How many nodes does it have? What are the resources allocated and what is their consumption like across the entire cluster?
Usage Details
What applications are running on it? What is the distribution of applications runs across users/departments? How much resources are these applications utilizing? Which of these applications are bursty in terms of resource utilization? Are some of these not running reliably due to lack of resources?
Let’s see how Unravel can help you discover and piece together such information:
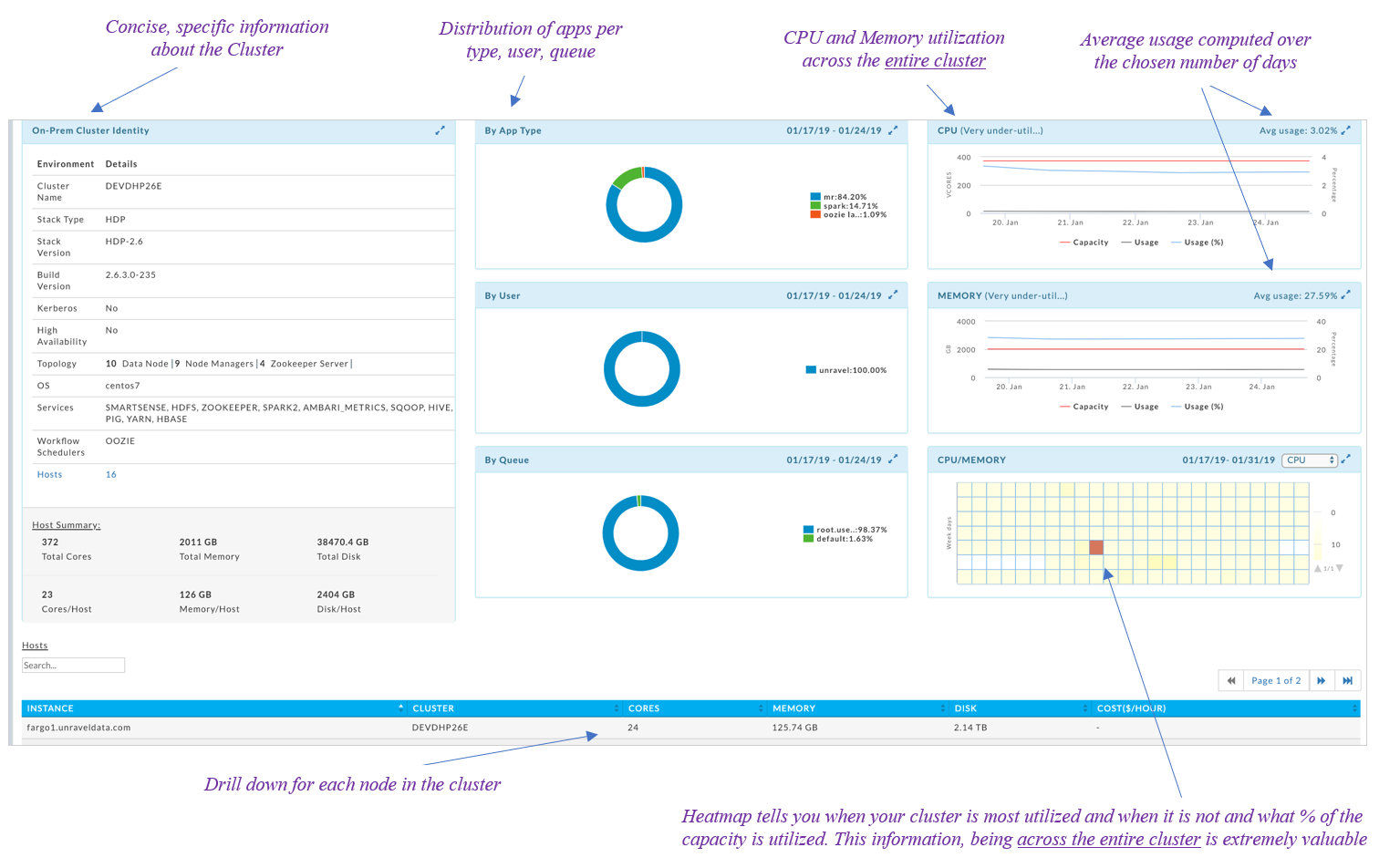
Unravel’s cluster discovery reporting
As you can see, Unravel provides a single pane of glass to display all of the relevant information e.g., services deployed, the topology of the cluster, cluster level stats (which have been suitably aggregated over the entire cluster’s resources) in terms of CPU, memory and disk.
The across-cluster heatmaps display the relative utilization of the cluster across time (a 24×7 view for each hour of say a week). If the utilization peaks at specific days and times of the week, you can plan on designing the cloud cluster such that it only scales for those precise times (keeping the costs low for when resources are not needed).
Unravel’s Cluster Discovery Report is purpose built for migrating data workloads to the cloud. All the relevant information is readily made available and all the number crunching is done to provide the most relevant details in a single pane of glass.
Identifying Applications Suitable for the Cloud
After developing an understanding of the cluster, the next step in the cloud migration journey is to figure out which modern data stack workloads may be most suitable to move to the cloud and would result in maximum benefits (e.g. in terms of increased SLA or reduce costs). So, it would be useful to discover applications of the following kinds for example:
Bursty in nature
Applications that take varying amounts of time to complete and/or resources can be good candidates to move to the cloud. These are typically frequently failing or highly variable applications due to lack of resources, contention and bottlenecks and could be better suited for the cloud so that they can run more reliably and SLAs can be met. Unravel can help you easily identify applications that are bursty in nature.
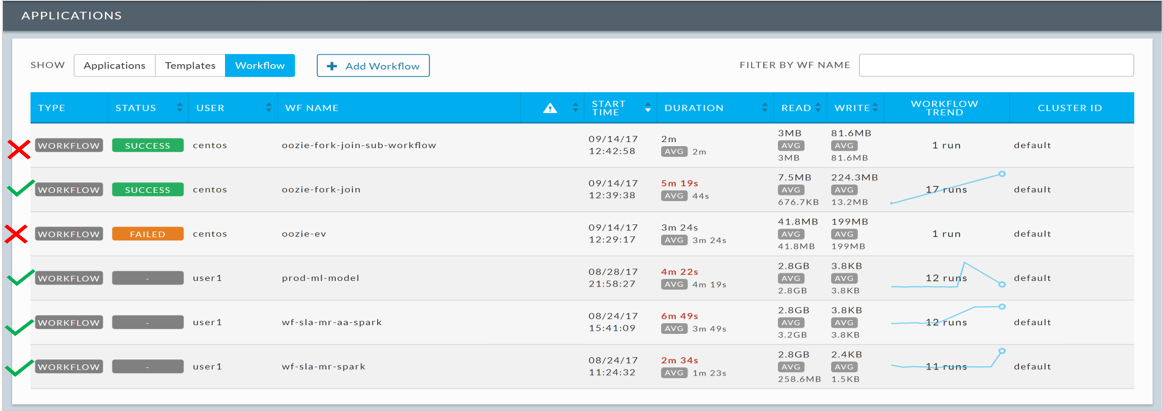
Discover apps that are bursty in nature using Unravel
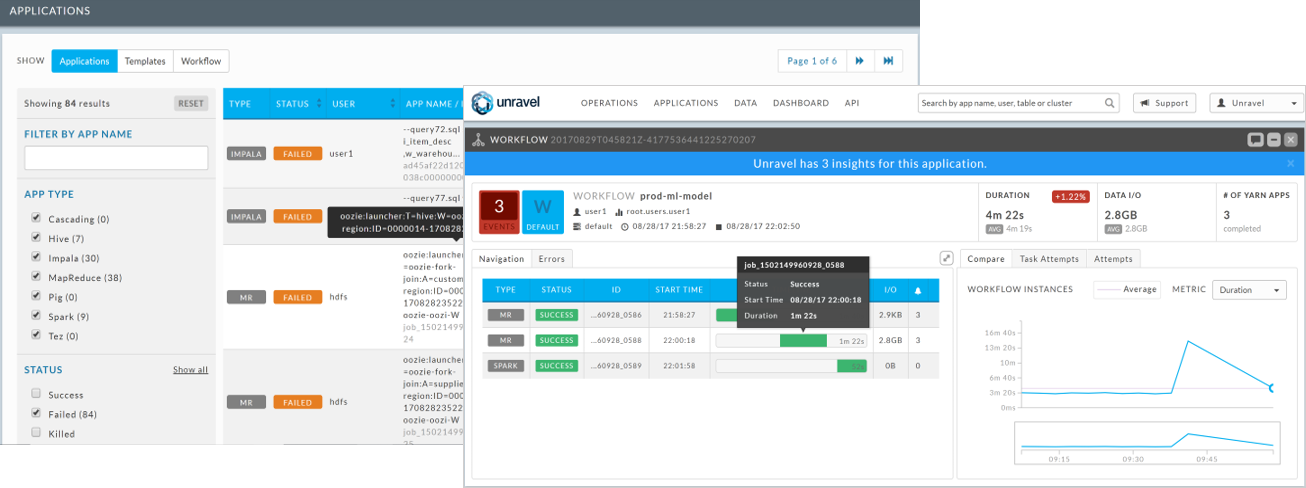
Unravel enables you to easily identify applications that could run more reliably in the cloud
Applications by tenants specific to the Business
Often, many corporations strategically decide to carry out the migration of modern data stack workloads to cloud in a phased manner. They may decide to migrate applications belonging to a specific users and/or queues first followed by others in a different phase (based on say the number of apps/resources used etc.). So, it becomes important to be able to have a clear view into distribution of these applications for various categories.
Unravel provides a clear graphical view into such information. Also, admins can explicitly tag certain application types in Unravel to achieve custom categorization such as grouping applications by department or project.
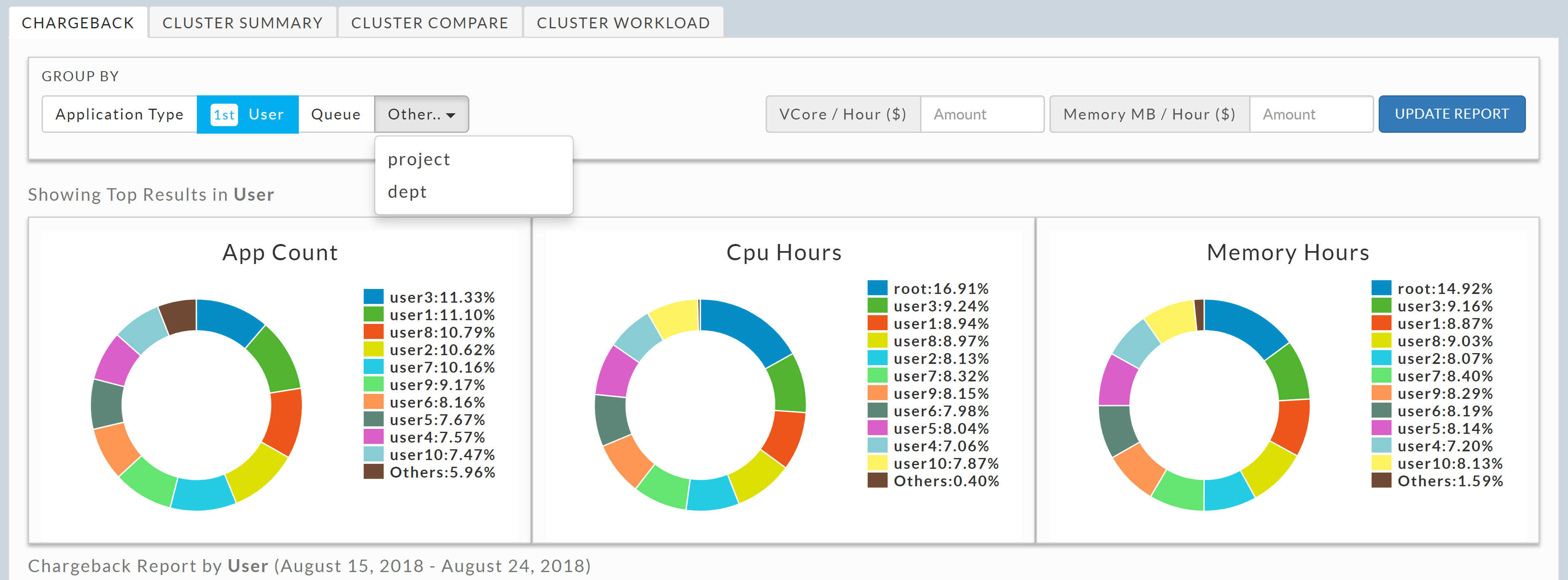
Unravel: Distribution of apps in different categories
Mapping your On-Premise Cluster to a Deployment Topology in the Cloud
Unravel provides you a mapping of your current on-premise environment to a cloud based one. Cloud Mapping Reports tell you the precise details of what type of VMs you would need, how many and what it would cost you.
You can choose different strategies for this mapping based on your goal(s). For each case, the resulting report will provide you the details of the cloud topology to match the goal.
In addition, each of these strategies are aware of multiple cloud providers (AWS EMR, Azure HDInsight, GCP etc.), the specs and cost of each VM, and optimize for mapping your actual workloads to the most effective VMs on the cloud.
Lift and Shift Strategy
This report provides a one to one mapping of each existing on-premise host to the most suitable instance type in Cloud in a way that It meets or exceeds the host’s hardware specs. This strategy ensures that your cloud deployment will have the same (or more) amount of resources available as your current on-premise environment and minimizes any risks associated with migrating to the cloud.
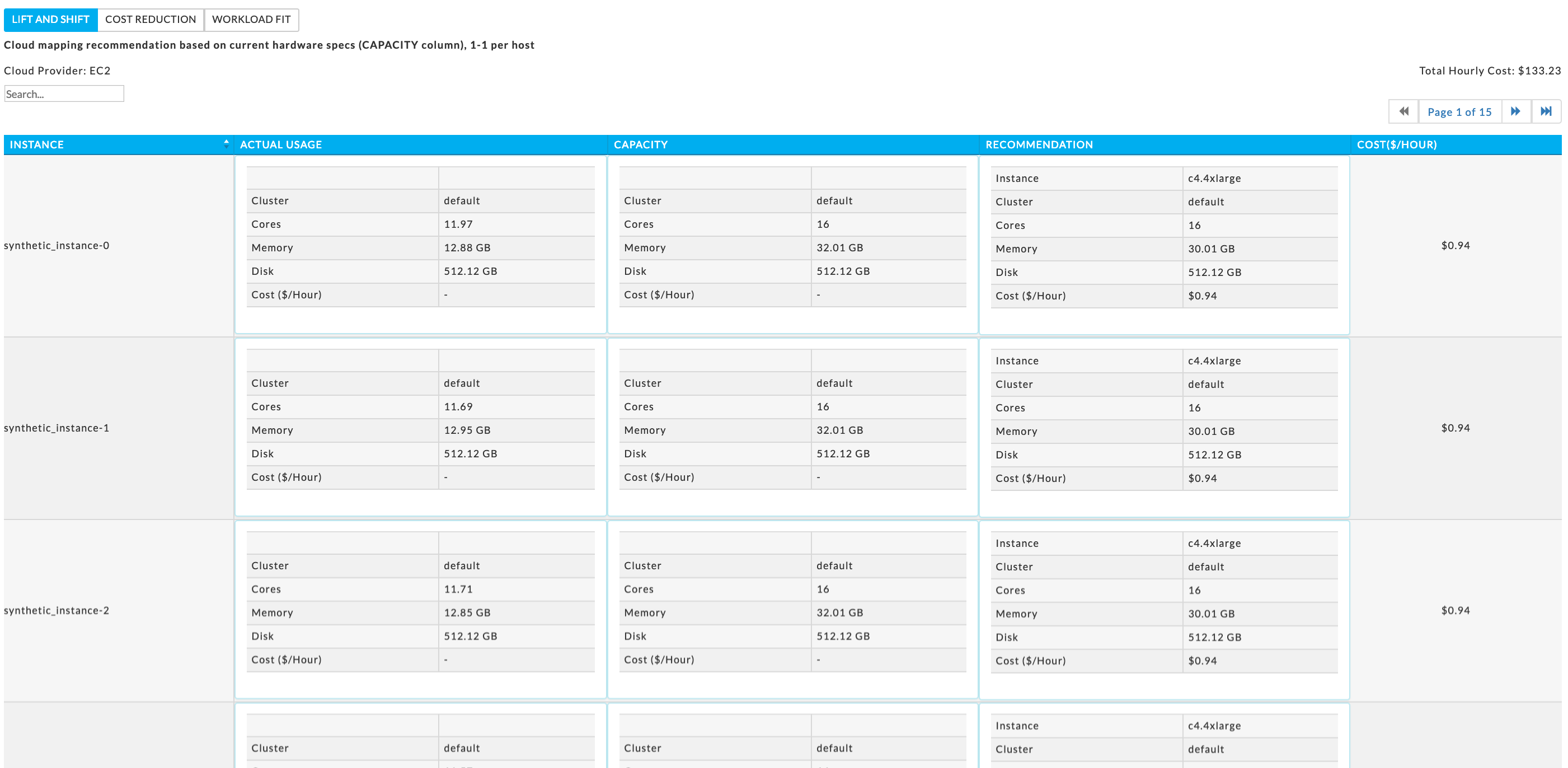
Unravel provides you a mapping of your current on-premise environment to a cloud based one. Strategy: Lift and Shift
Cost Reduction Strategy
This report provides a one to one mapping of each existing on-premise host to the most suitable Azure VM (or EC2/EMR/GCP) such that it matches the actual resource usage. This determines a cost optimum closest fit per host by matching the VM’s specs to the actual usage of the host. If your on-premise hosts are underutilized this method will always be less expensive than lift and shift.
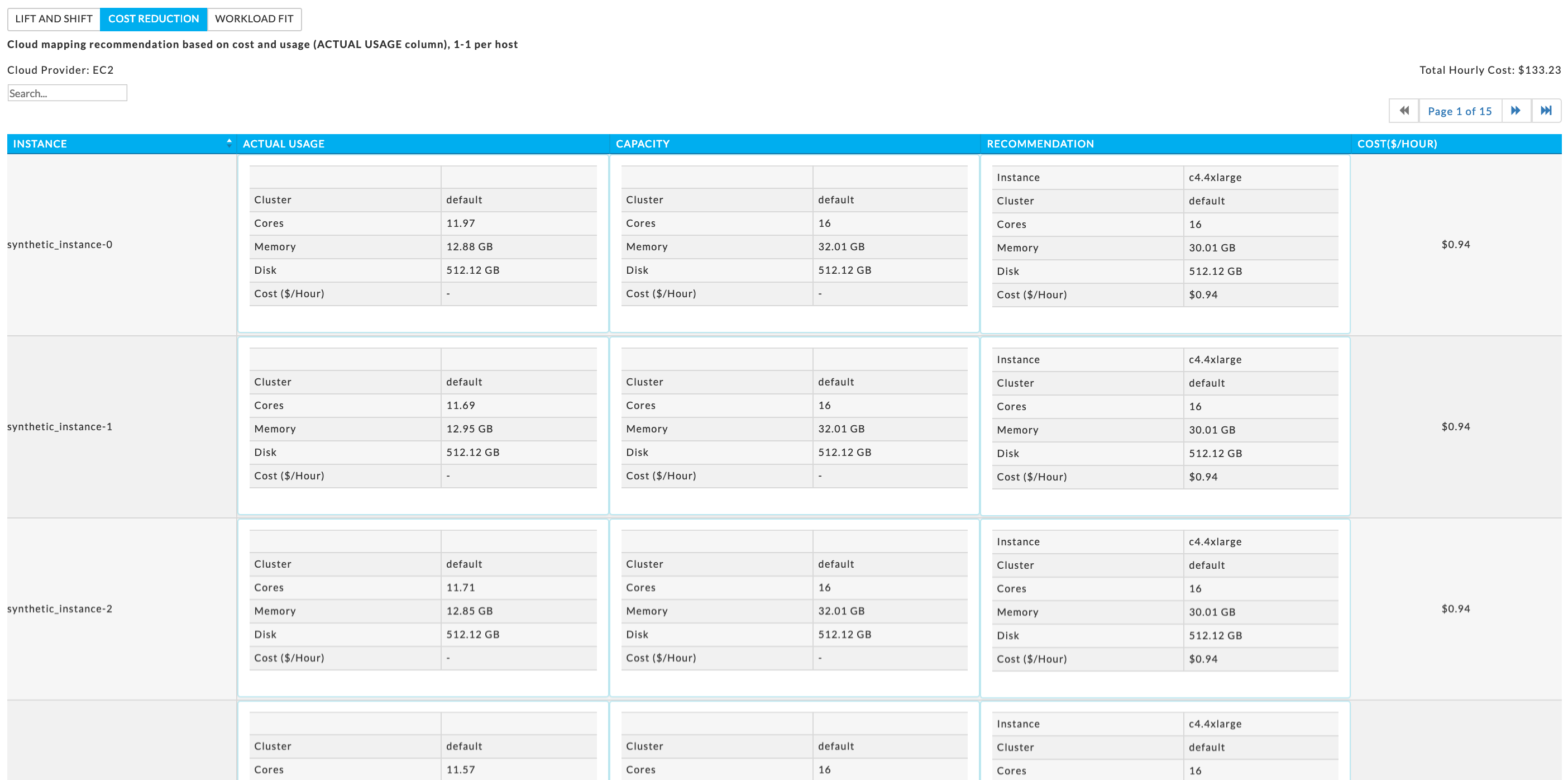
Unravel provides you a mapping of your current on-premise environment to a cloud based one. Strategy: Cost Reduction
Workload Fit Strategy
Unlike the other methods this is not a one-to-one mapping. Unravel analyzes your workload for the time period and bases it recommendations on that workload. Unravel provides multiple recommendations based on the resources needed to meet X% of your workloads. It determines the optimal assignment of VM types to meet the requirements while minimizing cost. This method is typically the most cost-effective method.

Unravel provides you a mapping of your current on-premise env. to a cloud based one. Strategy: “Workload Fit” (meeting requirements for 85% of the workloads)
The workload fit strategy also enables enterprises to pick the right price-to-performance trade-offs in the cloud. For example, in case less tight SLAs are acceptable, costs can be further reduced by choosing a less expensive VM type.
The above is a sampling of the mapping results showing the recommended cloud cluster topology for a given on-premise one. The mapping is done in accordance with the inputs from you about your specific organizational needs e.g. the specific provider you have decided to migrate to/the need to separate compute and storage or not/use of a specific set of instance types/discounts you get on pricing from the cloud providers and so on… You can even compare the costs for your specific case across different cloud providers and make a decision on the one that best suits your goals.
Unravel also provides a matching of services you have in your on-premise cluster with the ones made available by the specific cloud provider chosen (and whether it is a strong or weak match). The goal of this mapping is to give you a good sense of what applications may need some rewriting and which ones may be easily portable. For example, if you have been using Impala on your on-premise cluster, which is not available on EMR, we will suggest the closest service to use on migrating to EMR.
Also, are several other Unravel features and functionalities to best determine the way you should create the modern data stack cluster in the cloud. For example, check out the cluster workload heatmap:
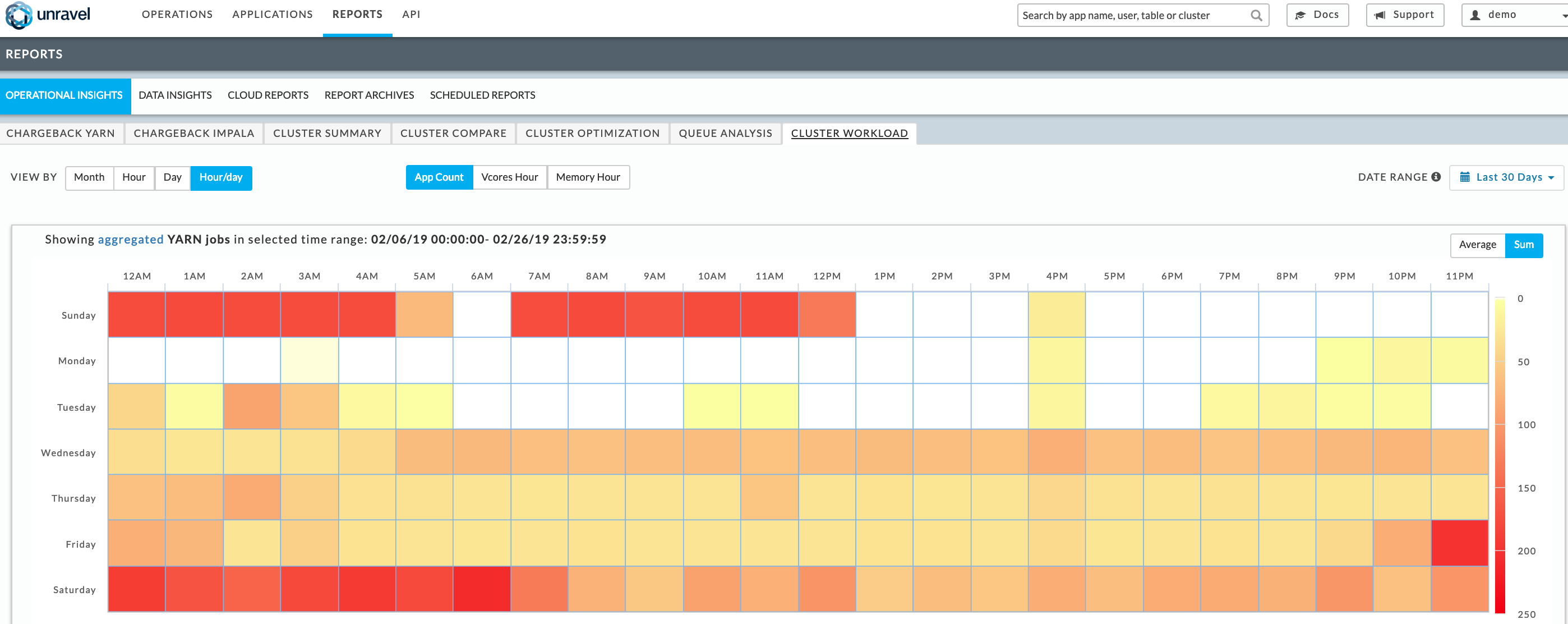
Heatmap of workload profile: Sunday has several hot hours, Saturday is the hottest day, Monday is hardly use and the cluster could be scaled down drastically on Mondays
As you can see above, Unravel analyzes and showcases seasonality to suggest how you can best make use of cloud’s auto-scaling capabilities. As you design your cloud cluster topology, you can use this information to setup appropriate processes for scaling-up and scaling-down clusters to ensure desired SLAs and reducing costs at the same time.
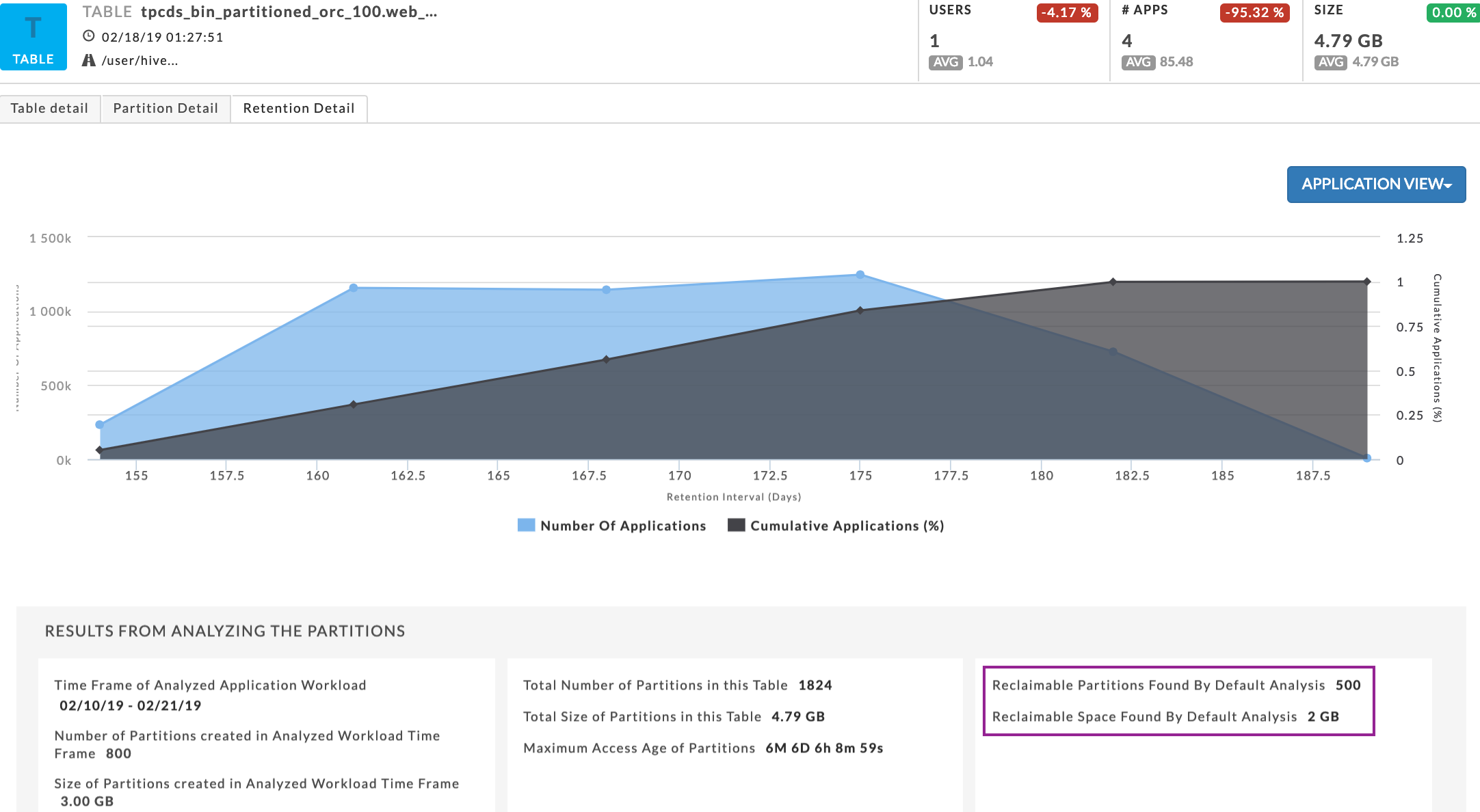
Decide on the best strategy for the storage in the cloud by looking at granular and specific information about the usage patterns of your tables and partitions in your on-premise cluster. Unravel can tell you which tables in your storage are least and most used and those that are used moderately.

Unravel can identify unused/cold data. You can decide on the appropriate layout for your data in the cloud accordingly and make the best use of your money
The determination of these labels is based on your specific configuration policy so it can be tailored to the business goals of your organization. Based on this information, you may decide to distribute these tables suitably across various types of storage in the cloud, e.g. most used ones on disk or high performant object storage e.g. AWS S3 Standard Storage/Azure Data Lake Storage Gen 2 (Hot) etc. and least used ones on lesser performant object storage e.g. AWS S3 Glacier Storage/Azure Data Lake Storage Gen 2 (Archive) etc. For example, in the example above, approximately half the data is never used and could be safely squared away to cheaper archival storage when moving to the cloud.
Unravel also provides you analysis on which partitions could possibly be reclaimed and hence some storage space could be saved. You have an opportunity to decide on a trade-off based on this information – store some partitions in archival storage in cloud or get rid of them altogether and reduce costs.
During and Post Migration: Tracking the Migration and its success
Unravel can help you track the success of the migration as you move your modern data stack applications from the on-premises cluster to the cloud cluster. You can use Unravel to compare how a given application was performing on-premise and how it is doing in its new home. If the performance is not up to par, Unravel’s insights and recommendations can help bring your migration on track.
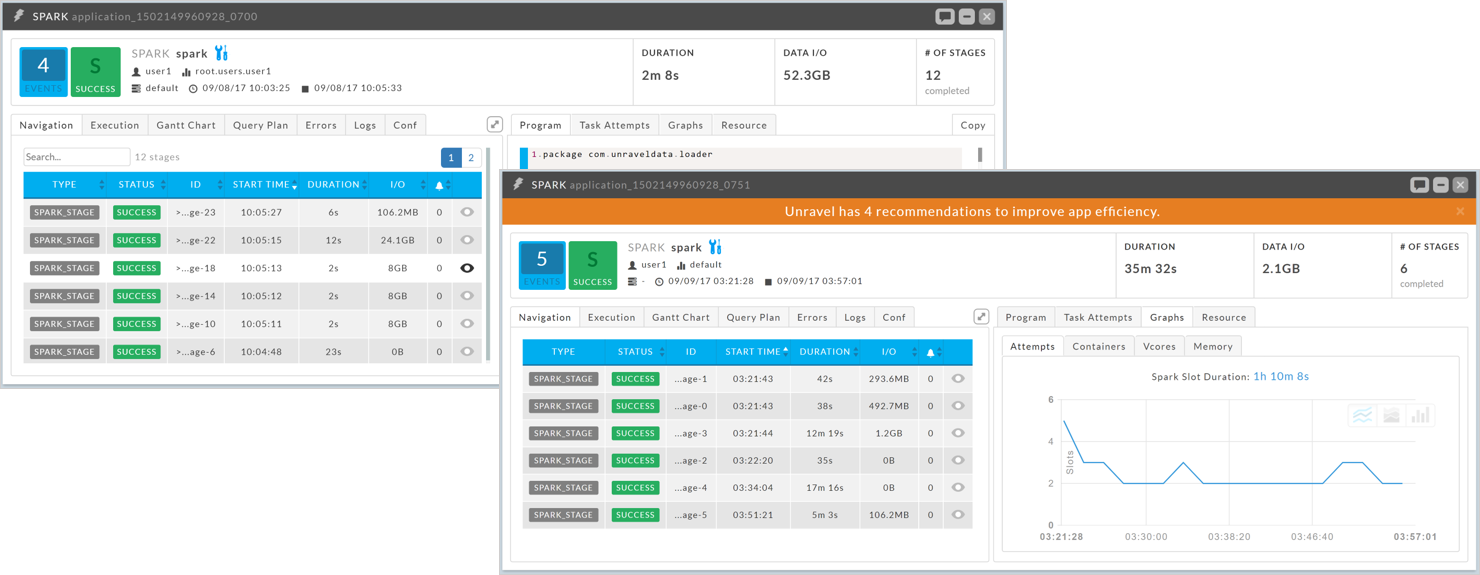
Compare how app is doing in new environment. This app is ~17 times slower on cloud. Unravel provides automatic fixes to get app back to meeting SLA.
End of Part I
Planning and migrating is, of course, only one step in the journey to realize the full value of big data in the cloud. In Parts II and III of the series, I will cover performance optimization, cloud cost reduction strategies; troubleshooting, debugging, and root cause analysis; and related topics.
In the meantime, check out the Unravel Cloud Data Operations Guide, which covers some of the topics from this blog series.