

Table of Contents
This is a guest blog by Arnab Ganguly, Senior Program Manager for Azure HDInsight at Microsoft. This blog was first published on the Microsoft Azure blog.
Migrating big data workloads to the cloud remains a key priority for our customers and Azure HDInsight is committed to making that journey simple and cost effective. HDInsight partners with Unravel whose mission is to reduce the complexity of delivering reliable application performance when migrating data from on-premises or a different cloud platform onto HDInsight. Unravel’s Application Performance Management (APM) platform brings a host of services towards providing unified visibility and operational intelligence to plan and optimize the migration process onto HDInsight.
- Identify current big data landscape and platforms for baselining performance and usage.
- Use advanced AI and predictive analytics to increase performance, throughput and to reduce application, data, and processing costs.
- Automatically size cluster nodes and tune configurations for the best throughput for big data workloads.
- Find, tier, and optimize storage choices in HDInsight for hot, warm, and cold data.
In our previous blog we discussed why the cloud is a great fit for big data and provided a broad view of what the journey to the cloud looks like, phase by phase. In this installment and the following parts we will examine each stage in that life cycle, diving into the planning, migration, operation and optimization phases. This blog post focuses on the planning phase.
Phase one: Planning
In the planning stage you must understand your current environment, determine high priority applications to migrate, and set a performance baseline to be able to measure and compare your on-premises clusters versus your Azure HDInsight clusters. This raises the following questions that need to be answered during the planning phase:
On-premises environment
- What does my current on-premises cluster look like, and how does it perform?
- How much disk, compute, and memory am I using today?
- Who is using it, and what apps are they running?
- Which of my workloads are best suited for migration to the cloud?
- Which big data services (Spark, Hadoop, Kafka, etc.) are installed?
- Which datasets should I migrate?
Azure HDInsight environment
- What are my HDInsight resource requirements?
- How do my on-premises resource requirements map to HDInsight?
- How much and what type of storage would I need on HDInsight, and how will my storage requirements evolve with time?
- Would I be able to meet my current SLAs or better them once I’ve migrated to HDInsight?
- Should I use manual scaling or auto-scaling HDInsight clusters, and with what VM sizes?
Baselining on-premises performance and resource usage
To effectively migrate big data pipelines from physical to virtual data centers, one needs to understand the dynamics of on-premises workloads, usage patterns, resource consumption, dependencies and a host of other factors.
Unravel creates on-premises cluster discovery reports in minutes
Unravel provides detailed reports of on-premises clusters including total memory, disk, number of hosts, and number of cores used. This cluster discovery report also delivers insights on cluster topology, running services, operating system version and more. Resource usage heatmaps can be used to determine any unique needs for Azure.
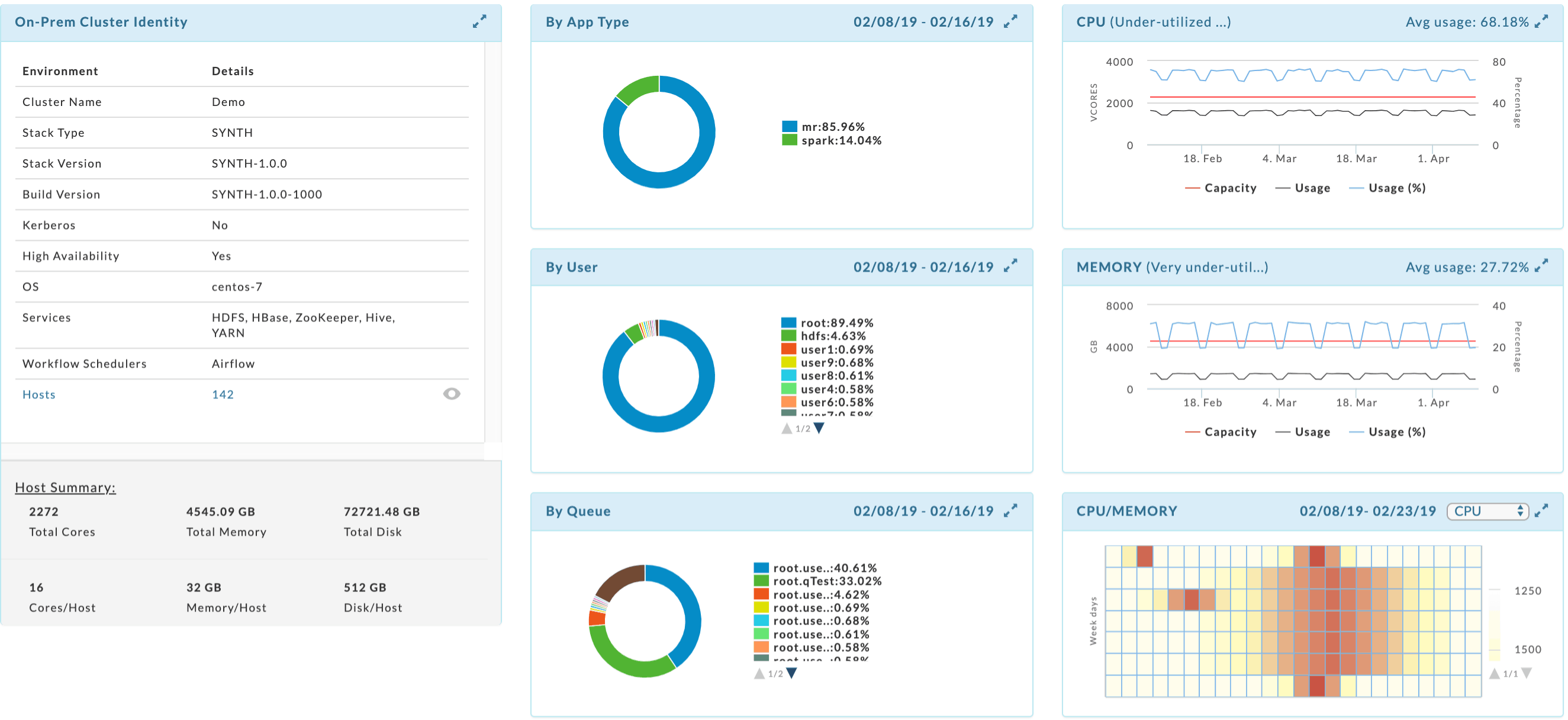
Unravel on-premises cluster discovery reporting
Gain key app usage insights from cluster workload analytics and data insights
Unravel can highlight application workload seasonality by user, department, application type and more to help calibrate and make the best use of Azure resources. This type of reporting can greatly aid in HDInsight cluster design choices (size, scale, storage, scalability options, etc.) to maximize your ROI on Azure expenses.
Unravel also provides data insights to enable decision making on the best strategy for storage in the cloud, by looking at specific metrics on usage patterns of tables and partitions in the on-premises cluster.
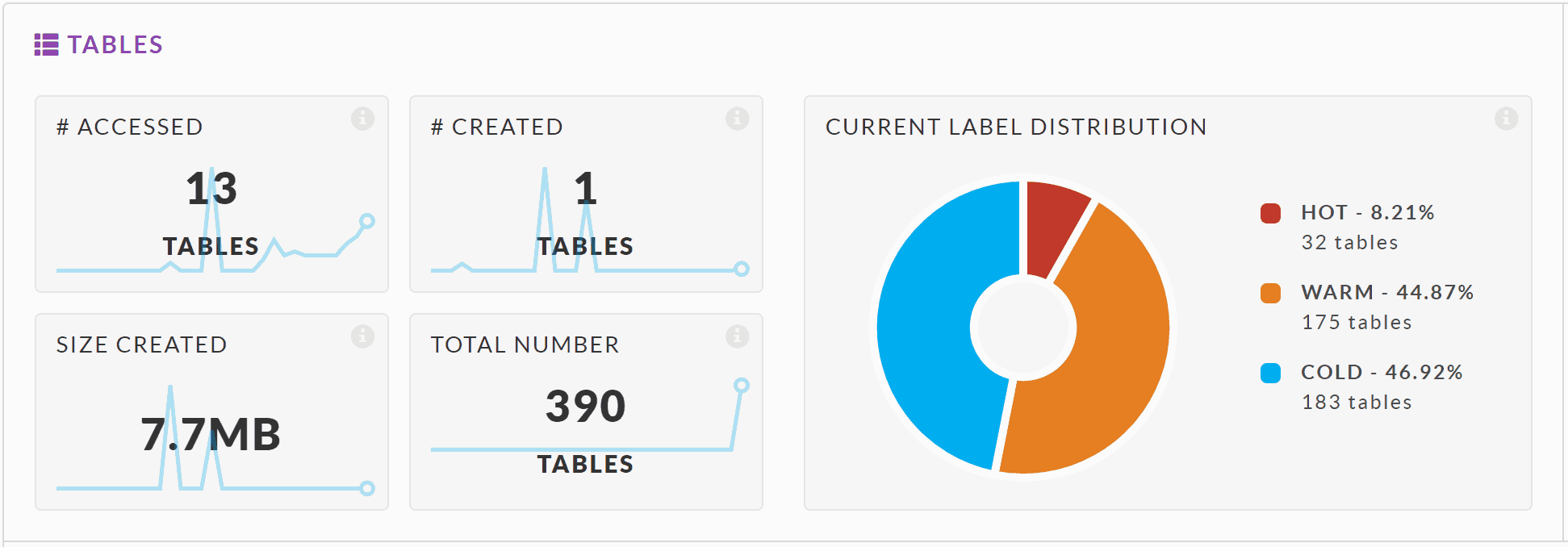
Unravel tiered storage detail for tables
It can also identify unused or cold data. Once identified, one can then decide on the appropriate layout for the data in the cloud accordingly and make the best use of their Azure budget. Based on this information, one can distribute datasets most effectively across HDInsight storage options. For example, hottest data can be stored on disk or the highly performant object storage of Azure Data Lake Storage Gen 2 (hot), and the least used ones on the relatively less performant Azure Blob storage (cold).
Data migration
Migrate on-premises data to Azure
There are two main options to migrate data from on-premises to Azure. Learn more information around the processes and data migration best practices.
- Transfer data over network with TLS
- Over the internet. Transfer data to Azure storage over a regular internet connection.
- Express Route. Create private connections between Microsoft datacenters and infrastructure on-premises or in a colocation facility.
- Data Box online data transfer. Data Box acts as network storage gateways to manage data between your site and Azure.
- Shipping data offline
- Import/Export service. Send physical disks to Azure and they will be uploaded for you.
- Data Box offline data transfer. This option helps you transfer large amounts of data to Azure when the network transfer isn’t an option.
Once you’ve identified which workloads to migrate, the planning gets a little more involved, requiring a proper APM tool to get the rest right. For everything to work properly in the cloud, you need to map out workload dependencies as they currently exist on-premises. This may be challenging when done manually, as these workloads rely on many different complex components. Incorrectly mapping these dependencies is one of the most common causes of big data application breakdowns in the cloud.
The Unravel platform provides a comprehensive and immediate readout of all the big data stack components involved in a workload. For example it could tell you that a streaming app is using Kafka, HBase, Spark, and Storm, and detail each component’s relationship with one another while also quantifying how much the app relies on each of these technologies. Knowing that the workload relies far more on Spark than Storm allows you to avoid under-provisioning Spark resources in the cloud and overprovisioning Storm.
Resource management and capacity planning
Organizations face a similar challenge in determining resource such as disk, compute, and memory that they will need for the workload to run efficiently on the cloud. It’s a challenge to determine utilization metrics of these resources for on-premises clusters, and which services are consuming them. Unravel provides reports that precisely bring forth quantitative metrics around resources consumed by each big data workload. If resources have been overprovisioned and thereby wasted, as many organizations unknowingly do, the platform provides recommendations to reconfigure applications to maximize efficiency and optimize spend. These resource settings are then translated to Azure.
Since cloud adoption is an ongoing and iterative process, customers might want to look ahead and think about how resource needs will evolve throughout the year as business needs change. Unravel leverages predictive analytics based on previous trends to determine resource requirements in the cloud for up to six months out.
For example, workloads such as fraud detection employ several datasets including ATM transaction data, customer account data, charge location data, and government fraud data. Once in Azure, some apps require certain datasets to remain in Azure in order to work properly, while other datasets can remain on-premises without issue. Like app dependency mapping it’s difficult to determine which datasets an app needs to run properly. Other considerations are security, data governance laws (some sensitive data must remain in private datacenters in certain jurisdictions), as well as the size of data. Based on Unravel’s resource management and capacity planning reports customers can efficiently manage data placement in HDInsight storage options and on-premises to best suit their business requirements.
Capacity planning and chargeback
Unravel brings some additional visibility and predictive capabilities that can remove a lot of mystery and guesswork around Azure migrations. Unravel analyzes your big data workloads for both on-premises or for Azure HDInsight, and can provide chargeback reporting by user, department, application type, queue, or other customer defined tags.
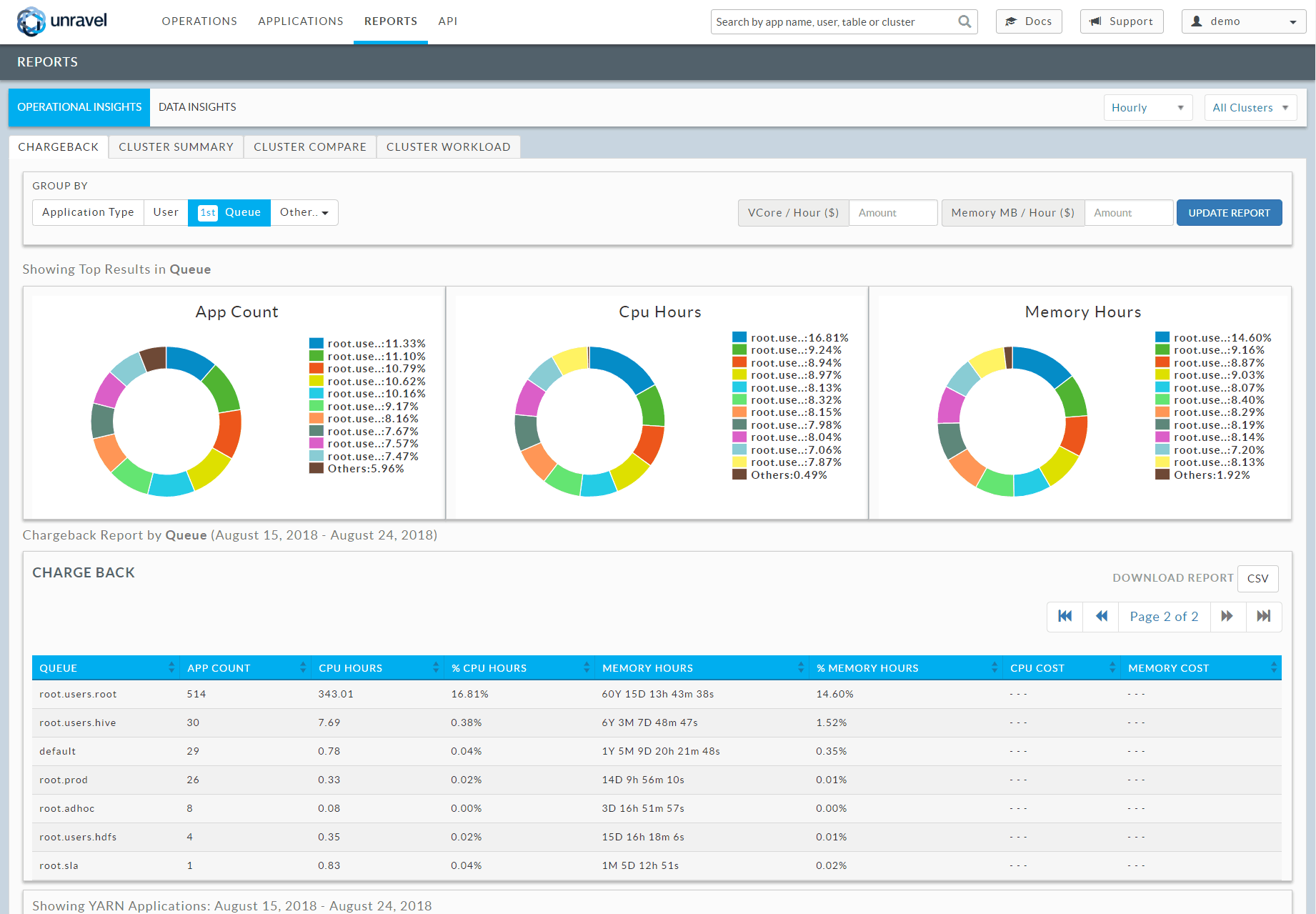
Unravel chargeback reporting by user, application, department, and more
Cluster sizing and instance mapping
As the final part of the planning phase, one will need to decide on the scale, VM sizes, and type of Azure HDInsight clusters to fit the workload type. This would depend on the business use case and priority of the given workload. For example a recommendation engine that needs to meet a stringent SLA at all times might require an auto-scaling HDInsight cluster so that it always has the compute resources it needs, but can also scale down during lean periods to optimize costs. Conversely if you have a workload that is fixed in resource requirements, such as a predictable batch processing app, one might want to deploy manual scaling HDInsight clusters, and size then optimally with the right VM sizes to keep costs under control.
Since choice of HDInsight VM instances is key to the success of the migration Unravel can infer the seasonality of big data workloads, and deliver recommendations for optimal server instance sizes in minutes instead of hours or days.
Unravel instance mapping by workload
Given the default virtual machine sizes for HDInsight clusters provided by Microsoft, Unravel provides some additional intelligence to help choose the correct virtual machine sizes for data workloads based on three different migration strategies:
- Lift and shift – If on-premises clusters collectively had 200 cores, 20 terabytes of storage, and 500 GB of memory Unravel will provide a close mapping to the Azure VM environment.This strategy ensures that the overall Azure HDInsight deployment will have the same (or more) of resources available as the current on-premises environment. This works to minimize any risks associated with under provisioning HDInsight for the migrating workloads.
- Cost reduction – This provides a one to one mapping of each existing on-premise host to the most suitable Azure Virtual Machine on HDInsight, such that it matches the actual resource usage. This determines a cost optimized closest fit per host by matching the VMs published specifications to the actual usage of the host. If your on-premise hosts are underutilized this method will always be less expensive than lift and shift.
- Workload fit – Consumes application runtime data that Unravel has collected, and offers the flexibility of provisioning Azure resources to provide 100 percent SLA compliance. Can also allow a bit of flexibility to choose a lower value, say 90 percent compliance as pictured below. The flexibility of the workload fit configuration enables the right price-to-performance trade-off in Azure.
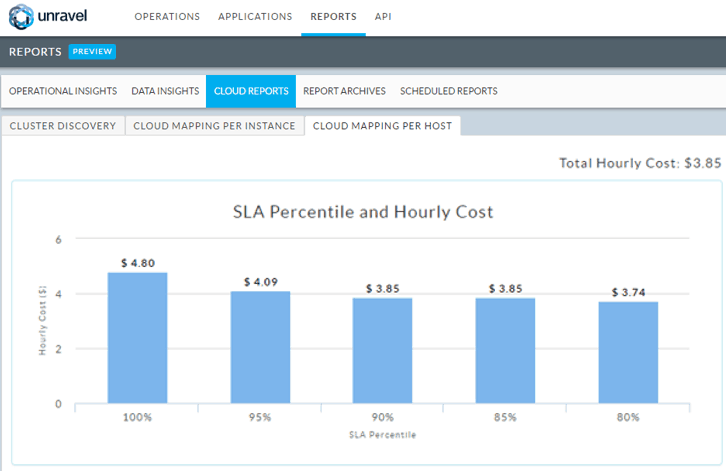
Unravel allows for flexibility around SLA compliance in capacity planning for your Azure clusters and can compute average hourly cost at each percentile.
Conclusion
The planning phase is the critical first step towards any workload migration to HDInsight. Many organizations lack effective quantitative and qualitative guidance like the ones provided by Unravel APM during the critical planning process, and may face challenges downstream in areas of workload execution and cost optimization. Unravel’s robust APM platform can help navigate this planning phase complexity by providing tools for mapping workload dependencies, forecasting resource usage, and guiding decisions on which datasets to move, and this in turn can make the migration process much more efficient, data driven, and ultimately successful.
In our upcoming blog, we’ll look closely at migration to HDInsight.