

Spark’s simple programming constructs and powerful execution engine have brought a diverse set of users to its platform. Many new modern data stack applications are being built with Spark in fields like healthcare, genomics, financial services, self-driving technology, government, and media. Things are not so rosy, however, when a Spark application fails.
Similar to applications in other distributed systems that have a large number of independent and interacting components, a failed Spark application throws up a large set of raw logs. These logs typically contain thousands of messages including errors and stacktraces. Hunting for the root cause of an application failure from these messy, raw, and distributed logs is hard for Spark experts; and a nightmare for the thousands of new users coming to the Spark platform. We aim to radically simplify root cause detection of any Spark application failure by automatically providing insights to Spark users like what is shown in Figure 1.

Figure 1: Insights from automatic root cause analysis improve Spark user productivity
Spark platform providers like Amazon, Azure, Databricks, and Google clouds as well as Application Performance Management (APM) solution providers like Unravel have access to a large and growing dataset of logs from millions of Spark application failures. This dataset is a gold mine for applying state-of-the-art artificial intelligence (AI) and machine learning (ML) techniques. In this blog, we look at how to automate the process of failure diagnosis by building predictive models that continuously learn from logs of past application failures for which the respective root causes have been identified. These models can then automatically predict the root cause when an application fails [1]. Such actionable root-cause identification improves the productivity of Spark users significantly.
Clues in the logs
A number of logs are available every time a Spark application fails. A distributed Spark application consists of a driver container and one or more executor containers. The logs generated by these containers have information about the application, as well as how the application interacts with the rest of the Spark platform. These logs form the key dataset that Spark users scan for clues to understand why an application failed.
However, the logs are extremely verbose and messy. They contain multiple types of messages, such as informational messages from every component of Spark, error messages in many different formats, stacktraces from code running on the Java Virtual Machine (JVM), and more. The complexity of Spark usage and internals make things worse. Types of failures and error messages differ across Spark SQL, Spark Streaming, iterative machine learning and graph applications, and interactive applications from Spark shell and notebooks (e.g., Jupyter, Zeppelin). Furthermore, failures in distributed systems routinely propagate from one component to another. Such propagation can cause a flood of error messages in the log and obscure the root cause.
Figure 2 shows our overall solution to deal with these problems and to automate root cause analysis (RCA) for Spark application failures. Overall, the solution consists of:
- Continuously collecting logs from a variety of Spark application failures
- Converting logs into feature vectors
- Learning a predictive model for RCA from these feature vectors
Of course, as with any intelligent solution that uses AI and ML techniques, the devil is the details!
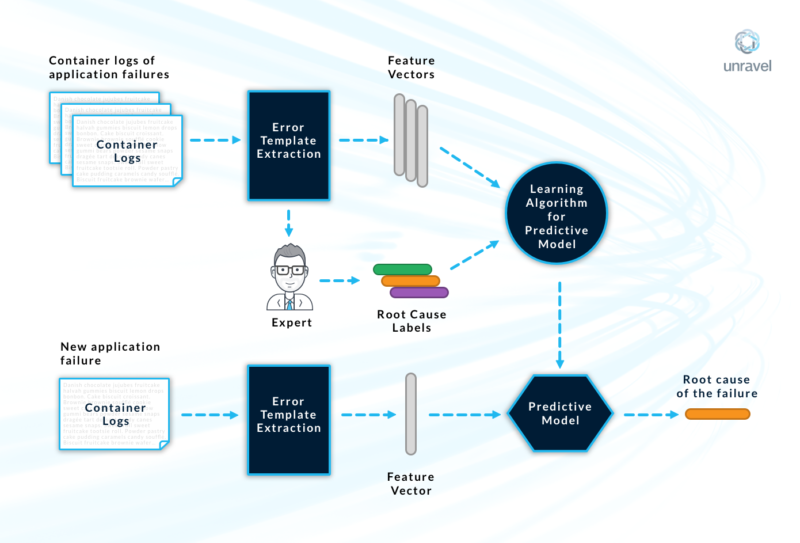
Figure 2: Root cause analysis of Spark application failures
Data collection for training: As the saying goes: garbage in, garbage out. Thus, it is critical to train RCA models on representative input data. In addition to relying on logs from real-life Spark application failures observed on customer sites, we have also invested in a lab framework where root causes can be artificially injected to collect even larger and more diverse training data.
Structured versus unstructured data: Logs are mostly unstructured data. To keep the accuracy of model predictions to a high level in automated RCA, it is important to combine this unstructured data with some structured data. Thus, whenever we collect logs, we are careful to collect trustworthy structured data in the form of key-value pairs that we additionally use as input features in the predictive models. These include Spark platform information and environment details of Scala, Hadoop, OS, and so on.
Labels: ML techniques for prediction fall into two broad categories: supervised learning and unsupervised learning. We use both techniques in our overall solution. For the supervised learning part, we attach root-cause labels with the logs collected from an application failure. This label comes from a taxonomy of root causes that we have created based on millions of Spark application failures seen in the field and in our lab. Broadly speaking, the taxonomy can be thought of as a tree data structure that categorizes the full space of root causes. For example, the first non-root level of this tree can be failures caused by:
- Configuration errors
- Deployment errors
- Resource errors
- Data errors
- Application errors
- Unknown factors
The leaves of this taxonomy tree form the labels used in the supervised learning techniques. In addition to a text label representing the root cause, each leaf also stores additional information such as: (a) a description template to present the root cause to a Spark user in a way that she will easily understand (like the message in Figure 1), and (b) recommended fixes for this root cause. We will cover the root-cause taxonomy in a future blog.
The labels are associated with the logs in one of two ways. First, the root cause is already known when the logs are generated, as a result of injecting a specific root cause we have designed to produce an application failure in our lab framework. The second way in which a label is given to the logs for an application failure is when a Spark domain expert manually diagnoses the root cause of the failure.
Input Features: Once the logs are available, there are various ways in which the feature vector can be extracted from these logs. One way is to transform the logs into a bit vector (e.g., 1001100001). Each bit in this vector represents whether a specific message template is present in the respective logs. A prerequisite to this approach is to extract all possible message templates from the logs. A more traditional approach for feature vectors from the domain of information retrieval is to represent the logs for a failure as a bag of words. This approach is mostly similar to the bit vector approach except for a couple of differences: (i) each bit in the vector now corresponds to a word instead of a message template, and (ii) instead of 0’s and 1’s, it is more common to use numeric values generated using techniques like TF-IDF.
More recent advances in ML have popularized vector embeddings. In particular, we use the doc2vectechnique [2]. At a high level, these vector embeddings map words (or paragraphs, entire documents) to multidimensional vectors by evaluating the order and placement of words with respect to their neighboring words. Similar words map to nearby vectors in the feature vector space. The doc2vec technique uses a 3-layer neural network to gauge the context of the document and relate similar content together.
Once the feature vectors are generated along with the label, a variety of supervised learning techniques can be applied for automatic RCA. We have evaluated both shallow as well as deep learning techniques including random forests, support vector machines, Bayesian classifiers, and neural networks.
Conclusion
The overall results produced by our solution are very promising and will be presented at Strata 2017 in New York. We are currently enhancing the solution in some key ways. One of these is to quantify the degree of confidence in the root cause predicted by the model in a way that users will easily understand. Another key enhancement is to speed up the ability to incorporate new types of application failures. The bottleneck currently is in generating labels. We are working on active learning techniques [3] that nicely prioritize the human efforts required in generating labels. The intuition behind active learning is to pick the unlabeled failure instances that provide the most useful information to build an accurate model. The expert labels these instances and then the predictive model is rebuilt.
Manual failure diagnosis in Spark is not only time-consuming but highly challenging due to correlated failures that can occur simultaneously. Our unique RCA solution enables the diagnosis process to function effectively even in the presence of multiple concurrent failures, as well as noisy data prevalent in production environments. Through automated failure diagnosis, we remove the burden of manually troubleshooting failed applications from the hands of Spark users and developers, enabling them to focus entirely on solving business problems with Spark.
To learn more about how to run Spark in production reliably, contact us.
[1] S. Duan, S. Babu, and K. Munagala, “Fa: A System for Automating Failure Diagnosis”, International Conference on Data Engineering, 2009
[2] Q. Lee and T. Mikolov, “Distributed Representations of Sentences and Documents”, International Conference on Machine Learning, 2014
[3] S. Duan and S. Babu, “Guided Problem Diagnosis through Active Learning“, International Conference on Autonomic Computing, 2008