

Mastering Databricks Cost Management and FinOps: A Comprehensive Checklist
In the era of big data and cloud computing, organizations increasingly turn to platforms like Databricks to handle their data processing and analytics needs. However, with great power comes great responsibility – and, in this case, the responsibility of managing costs effectively.
This checklist dives deep into cost management and FinOps for Databricks, exploring how to inform, govern, and optimize your usage while taking a holistic approach that considers code, configurations, datasets, and infrastructure.
While this checklist is comprehensive and very impactful when implemented fully, it can also be overwhelming to implement with limited staffing and resources. AI-driven insights and automation can solve this problem and are also explored at the bottom of this guide.
Understanding Databricks Cost Management
Before we delve into strategies for optimization, it’s crucial to understand that Databricks cost management isn’t just about reducing expenses. It’s about gaining visibility into where your spend is going, ensuring resources are being used efficiently, and aligning costs with business value. This comprehensive approach is often referred to as FinOps (Financial Operations).
The Holistic Approach: Key Areas to Consider
1. Code Optimization
Is code optimized? Efficient code is the foundation of cost-effective Databricks usage. Consider the following:
Query Optimization: Ensure your Spark SQL queries are optimized for performance. Use explain plans to understand query execution and identify bottlenecks.
Proper Data Partitioning: Implement effective partitioning strategies to minimize data scans and improve query performance.
Caching Strategies: Utilize Databricks’ caching mechanisms judiciously to reduce redundant computations.
2. Configuration Management
Are configurations managed appropriately? Proper configuration can significantly impact costs:
Cluster Sizing: Right-size your clusters based on workload requirements. Avoid over-provisioning resources.
Autoscaling: Implement autoscaling to adjust cluster size based on demand dynamically.
Instance Selection: Choose the appropriate instance types for your workloads, considering both performance and cost.
3. Dataset Management
Are datasets managed correctly? Efficient data management is crucial for controlling costs:
Data Lifecycle Management: Implement policies for data retention and archiving to avoid unnecessary storage costs.
Data Format Optimization: Use efficient file formats like Parquet or ORC to reduce storage and improve query performance.
Data Skew Handling: Address data skew issues to prevent performance bottlenecks and unnecessary resource consumption.
4. Infrastructure Optimization
Is infrastructure optimized? Optimize your underlying infrastructure for cost-efficiency:
Storage Tiering: Utilize appropriate storage tiers (e.g., DBFS, S3, Azure Blob Storage) based on data access patterns.
Spot Instances: Leverage spot instances for non-critical workloads to reduce costs.
Reserved Instances: Consider purchasing reserved instances for predictable, long-running workloads.
Implementing FinOps Practices
To truly master Databricks cost management, implement these FinOps practices:
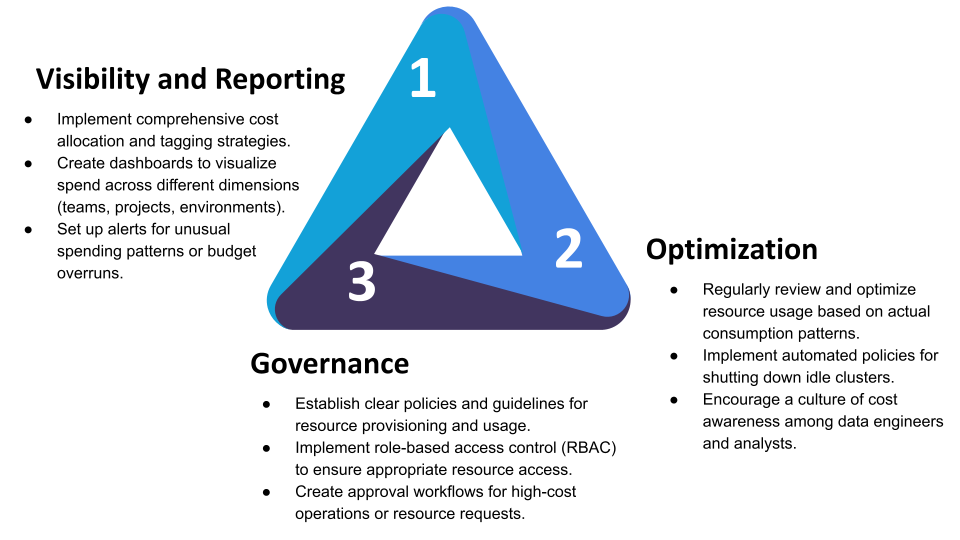
1. Visibility and Reporting
Implement comprehensive cost allocation and tagging strategies.
Create dashboards to visualize spend across different dimensions (teams, projects, environments).
Set up alerts for unusual spending patterns or budget overruns.
2. Optimization
Regularly review and optimize resource usage based on actual consumption patterns.
Implement automated policies for shutting down idle clusters.
Encourage a culture of cost awareness among data engineers and analysts.
3. Governance
Establish clear policies and guidelines for resource provisioning and usage.
Implement role-based access control (RBAC) to ensure appropriate resource access.
Create approval workflows for high-cost operations or resource requests.
Setting Up Guardrails
Guardrails are essential for preventing cost overruns and ensuring responsible usage:
Budget Thresholds: Set up budget alerts at various thresholds (e.g., 50%, 75%, 90% of budget).
Usage Quotas: Implement quotas for compute hours, storage, or other resources at the user or team level.
Automated Policies: Use Databricks’ Policy Engine to enforce cost-saving measures automatically.
Cost Centers: Implement chargeback or showback models to make teams accountable for their spend.
The Need for Automated Observability and FinOps Solutions
While manual oversight is important, the scale and complexity of modern data operations often necessitate automated solutions. Tools like Unravel can provide:
Real-time cost visibility across your entire Databricks environment.
Automated recommendations for cost optimization.
Anomaly detection to identify unusual spending patterns quickly.
Predictive analytics to forecast future costs and resource needs.
These solutions can significantly enhance your ability to manage costs effectively, providing insights that would be difficult or impossible to obtain manually.
Conclusion
Effective cost management and FinOps for Databricks require a holistic approach considering all aspects of your data operations. By optimizing code, configurations, datasets, and infrastructure, and implementing robust FinOps practices, you can ensure that your Databricks investment delivers maximum value to your organization. Remember, the goal isn’t just to reduce costs, but to optimize spend and align it with business objectives. With the right strategies and tools in place, you can turn cost management from a challenge into a competitive advantage.
To learn more about how Unravel can help with Databricks cost management, request a health check report, view a self-guided product tour, or request a demo.