

Table of Contents
The DataOps Unleashed conference, founded this year by Unravel Data, was full of interesting presentations and discussions. We described the initial keynote and some highlights from the first half of the day in our DataOps Unleashed Part 1 blog post. Here, in Part 2, we bring you highlights through the end of the day: more about what DataOps is, and case studies as to how DataOps is easing and speeding data-related workflows in big, well-known companies.
You can freely access videos from DataOps Unleashed – most just 30 minutes in length, with a lot of information packed into hot takes on indispensable technologies and tools, key issues, and best practices. We highlight some of the best-received talks here, but we also urge you to check out any and all sessions that are relevant to you and your work.
Mastercard Pre-Empts Harmful Workloads
See the Mastercard session now, on-demand.
Chinmay Sagade and Srinivasa Gajula of Mastercard are responsible for helping the payments giant respond effectively to the flood of transactions that has come their way due to the pandemic, with cashless, touchless, and online transactions all skyrocketing. And much of the change is likely to be permanent, as approaches to doing business that were new and emerging before 2020 become mainstream.
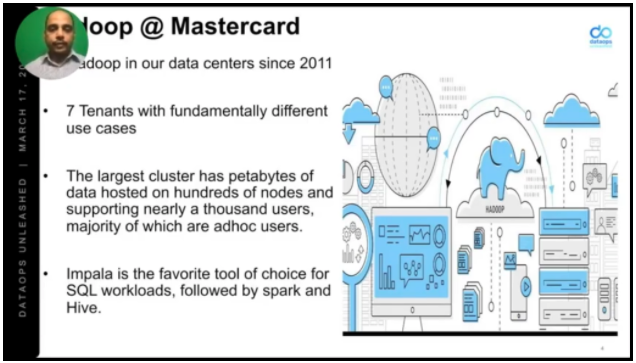
Hadoop is a major player at Mastercard. Their largest cluster is petabytes in size, and they use Impala for SQL workloads, as well as Spark and Hive. But they have in the past been plagued by services being unavailable, applications failing, and bottlenecks caused by suboptimalsub-optimal use of workloads.

Mastercard has used Unravel to help application owners self-tune their workloads and to create an automated monitoring system to detect toxic workloads and automatically intervene to prevent serious problems. For instance, they proactively detect large broadcast joins in Impala, which tend to consume tremendous resources. They also detect cross-joins in queries.
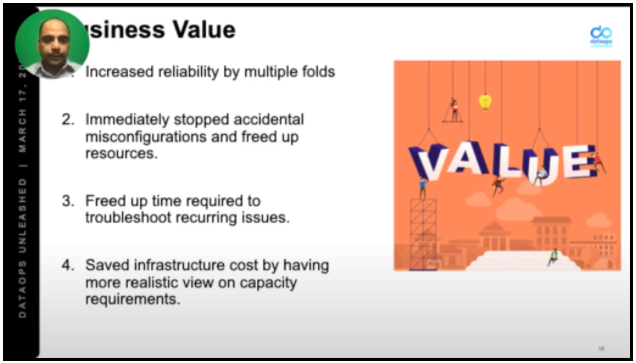
Their work has delivered tremendous business value:
- Vastly improve reliability
- Better configurations free up resources
- Reduced problems free up time for troubleshooting recurring issues
- Better capacity usage and forecasting saves infrastructure costs
To the team’s surprise, users were hugely supportive of restrictions, because they could see the positive impact on performance and reliability. And the entire estate now works much better, freeing resources for new initiatives.
Take the hassle out petabyte-scale DataOps
Gartner CDO DataOps Panel Shows How to Maximize Opportunities
See the Gartner CDO Panel now, on-demand.
As the VP in charge of big data and advanced analytics for leading industry analysts, Gartner, Sanjeev Mohan has seen it all. So he had some incisive questions for his panel of four CDOs. A few highlights follow.
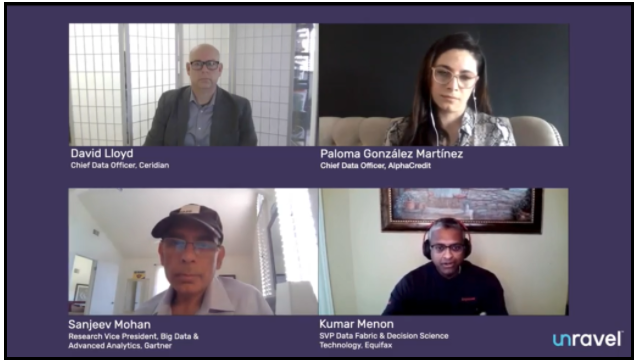
Paloma Gonzalez Martinez is CDO at AlphaCredit, one of the fastest-growing financial technology companies in Latin America. She was asked: How has data architecture evolved? And, if you had a chance to do your big data efforts over again, how would you do things differently?
Paloma shared that her company actually is revisiting their whole approach. The data architecture was originally designed around data; AlphaCredit is now re-architecting around customer and business needs.
David Lloyd is CDO at Ceridian, a human resources (HR) services provider in the American Midwest. David weighed in on the following: What are the hardest roles to fill on your data team? And, how are these roles changing?
David said that one of the guiding principles he uses in hiring is to see how a candidate’s eyes light up around data. What opportunities do they see? How do they want to help take advantage of them?
Kumar Menon is SVP of Data Fabric and Decision Science Technology at Equifax, a leading credit bureau. With new candidates, Kumar looks for the combination of the intersection of engineering and insights. How does one build platforms that identify crucial features, then share them quickly and effectively? When does a model need to be optimized, and when does it need to be rebuilt?
Sarah Gadd is Head of Semantic Technology, Analytics and Machine Intelligence at Credit Suisse. (Credit Suisse recently named Unravel Data a winner of their 2021 Disruptive Technologies award.) Technical problems disrupted Sarah from participating live, but she contributed answers to the questions that were discussed.
Sarah looks for storytellers to help organize data and analytics understandably, and is always on the lookout for technical professionals who deeply understand the role of the semantic layer in data models. And in relation to data architecture, the team faces a degree of technical debt, so innovation is incremental rather than sweeping at this point.
84.51°/Kroger Solves Contention and the Small Files Problem with DataOps Techniques
See the 84.51/Kroger session now, on-demand.
Jeff Lambert and Suresh Devarakonda are DataOps leaders at the 84.51° analytics business of retailing giant Kroger. Their entire organization is all about deriving value from data and delivering that value to Kroger, their customers, partners, and suppliers. They use Yarn and Impala as key tools in their data stack.
They had a significant problem with jobs that created hundreds of small files, which consumed system resources way out of proportion to the file sizes. They have built executive dashboards that have helped stop finger-pointing, and begin solving problems based on shared, trusted information.
Unravel Data has been a key tool in helping 84.51° to adopt a DataOps approach and get all of this done. They are expanding their cloud presence on Azure, using Databricks and Snowflake. Unravel gives them visibility, management capability, and automatically generated actions and recommendations, making their data pipelines work much better. 84.51 has just completed a proof of concept (PoC) for Unravel on Azure and Databricks, and are heavily using recently introduced Spark 3.0 support.
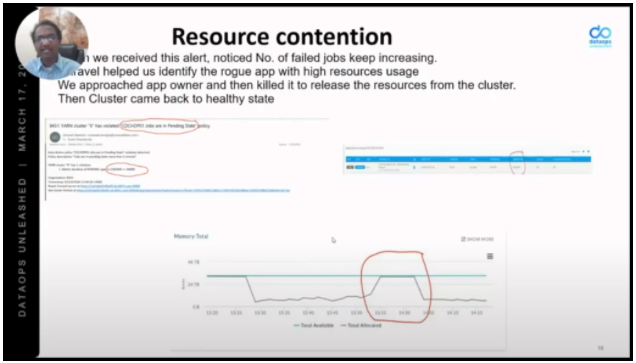
Resource contention was caused by a rogue app that spiked memory usage. Using Unravel, 84.51° quickly found the offending app, killed it, and worked with the owner to prevent the problem in the future. 84.51 now proactively scans for small files and concerning issues using Unravel, heading off problems in advance. Unravel also helps move problems up to a higher level of abstraction, so operations work doesn’t require that operators be expert in all of the technologies they’re responsible for managing.
At 84.51°, Unravel has helped the team improve not only their own work, but what they deliver to the company:
- Solving the small files problem improves performance and reliability
- Spotting and resolving issues early prevents disruption and missed SLAs
- Improved resource usage and availability saves money and increases trust
- More production from less investment allows innovation to replace disruption
Cutting Cloud Costs with Amazon EMR and Unravel Data
See the AWS session now, on-demand.
As our own Sandeep Uttamchandani says, “Once you get into the cloud, ‘pay as you go’ takes on a whole new meaning: as you go, you pay.” But AWS Solutions Architect Angelo Carvalho is here to help. AWS understands that their business will grow healthier if customers are wringing the most value out of their cloud costs, and Angelo uses this talk to help people do so.
Angelo describes the range of AWS services around big data, including EMR support for Spark, Hie, Presto, HBase, Flink, and more. He emphasized EMR Managed Scaling, which makes scaling automatic, and takes advantage of cloud features to save money compared to on-premises, where you need to have enough servers all the time to support peak workloads that only occur some of the time. (And where you can easily be overwhelmed by unexpected spikes.)

Angelo was followed by Kunal Agarwal of Unravel Data, who showed how Unravel optimizes EMR. Unravel creates an interconnected model of the data in EMR and applies predictive analytics and machine learning to it. Unravel automatically optimizes some areas, offers alerts for others, and provides dashboards and reports to help you manage both price and performance.
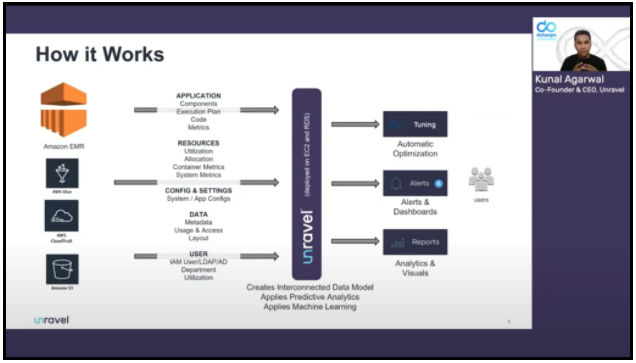
Kunal then shows how this actually works in Unravel, demonstrating a few key features, such as automatically generated, proactive recommendations for right-sizing resource use and managing jobs. The lessons from this session apply well beyond EMR, and even beyond the cloud, to anyone who needs to run their jobs with the highest performance and the most efficient use of available resources.
Need to get cloud overspending under control?
Microsoft Describes How to Modernize your Data Estate
See the Microsoft session now, on-demand.
According to Priya Vijayarajendran, VP for Data and AI at Microsoft, a modern, cloud-based strategy underpins success in digital transformation. Microsoft is enabling this shift for customers and undertaking a similar journey themselves.
Priya describes data as a strategic asset. Managing data is not a liability or a problem, but a major opportunity. She shows how even a simplified data estate is very complex, requiring constant attention.

Priya tackled the “what is DataOps” challenge, using DevOps techniques, agile, and statistics, processes, and control methodologies to intelligently manage data as a strategic asset. She displayed a reference architecture for continuous integration and continuous delivery on the Azure platform.
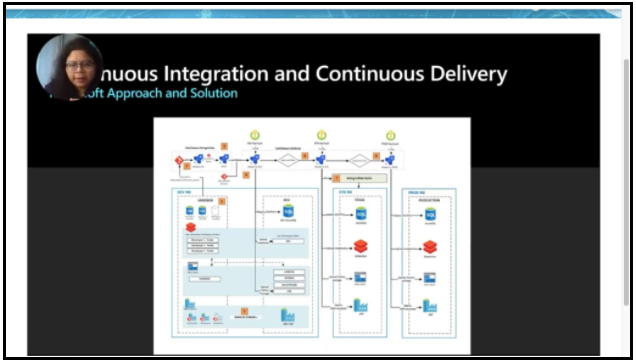
Priya ended by offering to interact with the community around developing ever-better answers to the challenges and opportunities that data provides, whether on Microsoft platforms or more broadly. Microsoft is offering multi-cloud products that work on AWS and Google Cloud Platform as well as Azure. She said that governance should not be restrictive, but instead should enable people to do more.

A Superset of Advanced Topics for Data Engineers
See the Apache Superset session now, on-demand.
Max Beauchemin is the creator of Airflow and currently CEO at Preset, the company that is bringing Apache Superset to the market. Superset is the leading open-source analytics platform and is widely used at major companies. Max is the original creator of Apache Airflow, mentioned in our previous Unleashed blog post, as well as Superset. Preset makes Superset available as a managed service in the cloud.
Max discussed high-end, high-impact topics around Superset. He gave a demo, then demonstrated SQL Lab, a SQL development environment built in React. He then showed how to build a visualization plugin; creating alerts, reports, charts and dashboards; and using the Superset Rest API.
Templating is a key feature in SQL Lab, allowing users to build a framework that they can easily adapt to a wide variety of SQL queries. Built on Python, Jinja allows you to use macros in your SQL code. Jinja integrates with Superset, Airflow, and other open source technologies. A parameter can be specified as type JSON, so values can be filled in at runtime.
With this talk, Max gave the audience the information they need to plan, and begin to implement, ambitious Superset projects that work across a range of technologies.
Soda Delivers a Technologist’s Call to Arms for DataOps
See the Soda DataOps session now, on-demand.
What does DataOps really mean to practitioners? Vijay Karan, Head of Data Engineering at Soda, shows how DataOps applies at each stage of moving data across the stack, from ingest to analytics.
Soda is a data monitoring platform that supports data integrity, so Vijay is in a good position to understand the importance of DataOps. He discusses core principles of DataOps and how to apply those principles in your own projects.
Vijay begins with the best brief description of DataOps, from a practitioner’s point of view, that we’ve heard yet:
What is DataOps?
A process framework that helps data teams deliver high quality, reliable data insights with high velocity.
At just sixteen words, this is admirably concise. In fact, to boil it down to just seven words, “A process framework that helps data teams” is not a bad description.
Vijay goes on to share half a dozen core DataOps principles, and then delivers a deep dive on each of them.

Here at Unravel, part of what we deliver is in his fourth principle:
Improve Observability
Monitor quality and performance metrics across data flows
Just in this one area, if everyone did what Vijay suggests around this – defining metrics, visualizing them, configuring meaningful alerts – the world would be a calmer and more productive place.
Conclusion
This wraps up our overview description of DataOps Unleashed. If you haven’t already done so, please check out Part 1, highlighting the keynote and talks discussing Adobe, Cox Automotive, Airflow, Great Expectations, DataOps, and moving Snowflake to space.
However, while this blog post gives you some idea as to what happened, nothing can take the place of “attending” sessions yourself, by viewing the recordings. You can view the videos from DataOps Unleashed here. You can also download The Unravel Guide to DataOps, which was made available for the first time during the conference.
Finding Out More
Read our blog post Why DataOps Is Critical for Your Business.