

By Craig Wiley, Senior Director of Product Management, Databricks and Clinton Ford, Director of Product Marketing, Unravel Data
Introduction
Machine learning (ML) enables organizations to extract more value from their data than ever before. Companies who successfully deploy ML models into production are able to leverage that data value at a faster pace than ever before. But deploying ML models requires a number of key steps, each fraught with challenges:
- Data preparation, cleaning, and processing
- Feature engineering
- Training and ML experiments
- Model deployment
- Model monitoring and scoring
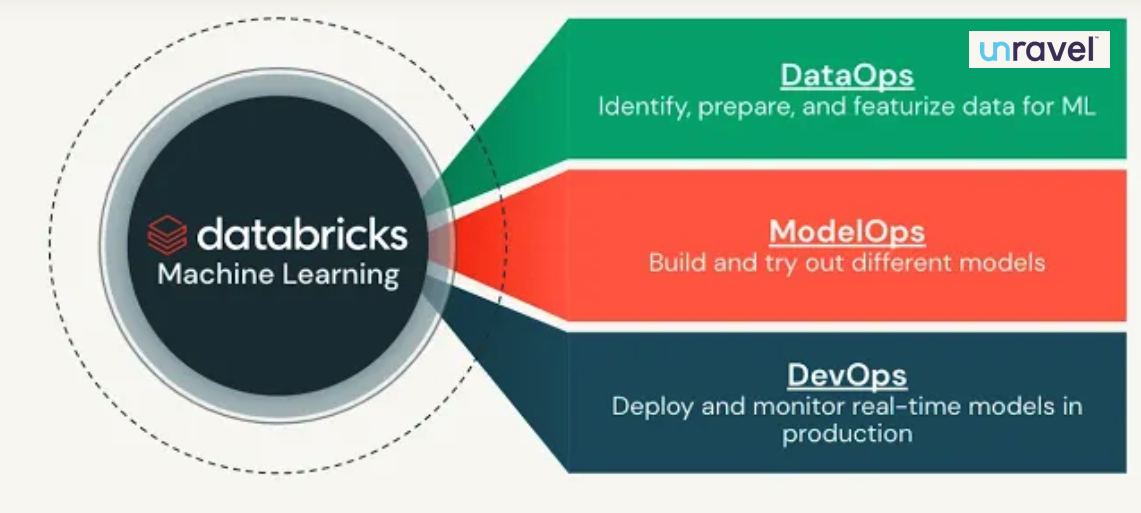
Figure 1. Phases of the ML lifecycle with Databricks Machine Learning and Unravel Data
Challenges at each phase
Data preparation and processing
Data preparation is a data scientist’s most time-consuming task. While there are many phases in the data science lifecycle, an ML model can only be as good as the data that feeds it. Reliable and consistent data is essential for training and machine learning (ML) experiments. Despite advances in data processing, a significant amount of effort is required to load and prepare data for training and ML experimentation. Unreliable data pipelines slow the process of developing new ML models.
Training and ML experiments
Once data is collected, cleansed, and refined, it is ready for feature engineering, model training, and ML experiments. The process is often tedious and error-prone, yet machine learning teams also need a way to reproduce and explain their results for debugging, regulatory reporting, or other purposes. Recording all of the necessary information about data lineage, source code revisions, and experiment results can be time-consuming and burdensome. Before a model can be deployed into production, it must have all of the detailed information for audits and reproducibility, including hyperparameters and performance metrics.
Model deployment and monitoring
While building ML models is hard, deploying them into production is even more difficult. For example, data quality must be continuously validated and model results must be scored for accuracy to detect model drift. What makes this challenge even more daunting is the breadth of ML frameworks and the required handoffs between teams throughout the ML model lifecycle– from data preparation and training to experimentation and production deployment. Model experiments are difficult to reproduce as the code, library dependencies, and source data change, evolve, and grow over time.
The solution
The ultimate hack to productionize ML is data observability combined with scalable, serverless, and automated ML model serving. Unravel’s AI-powered data observability for Databricks on AWS and Azure Databricks simplifies the challenges of data operations, improves performance, saves critical engineering time, and optimizes resource utilization.
Databricks Model Serving deploys machine learning models as a REST API, enabling you to build real-time ML applications like personalized recommendations, customer service chatbots, fraud detection, and more – all without the hassle of managing serving infrastructure.
Databricks + data observability
Whether you are building a lakehouse with Databricks for ML model serving, ETL, streaming data pipelines, BI dashboards, or data science, Unravel’s AI-powered data observability for Databricks on AWS and Azure Databricks simplifies operations, increases efficiency, and boosts productivity. Unravel provides AI insights to proactively pinpoint and resolve data pipeline performance issues, ensure data quality, and define automated guardrails for predictability.
Scalable training and ML experiments with Databricks
Databricks uses pre-installed, optimized libraries to build and train machine learning models. With Databricks, data science teams can build and train machine learning models. Databricks provides pre-installed, optimized libraries. Examples include scikit-learn, TensorFlow, PyTorch, and XGBoost. MLflow integration with Databricks on AWS and Azure Databricks makes it easy to track experiments and store models in repositories.
MLflow monitors machine learning model training and running. Information about the source code, data, configuration information, and results are stored in a single location for quick and easy reference. MLflow also stores models and loads them in production. Because MLflow is built on open frameworks, many different services, applications, frameworks, and tools can access and consume the models and related details.
Serverless ML model deployment and serving
Databricks Serverless Model Serving accelerates data science teams’ path to production by simplifying deployments and reducing mistakes through integrated tools. With the new model serving service, you can do the following:
- Deploy a model as an API with one click in a serverless environment.
- Serve models with high availability and low latency using endpoints that can automatically scale up and down based on incoming workload.
- Safely deploy the model using flexible deployment patterns such as progressive rollout or perform online experimentation using A/B testing.
- Seamlessly integrate model serving with online feature store (hosted on Azure Cosmos DB), MLflow Model Registry, and monitoring, allowing for faster and error-free deployment.
Conclusion
You can now train, deploy, monitor, and retrain machine learning models, all on the same platform with Databricks Model Serving. Integrating the feature store with model serving and monitoring helps ensure that production models are leveraging the latest data to produce accurate results. The end result is increased availability and simplified operations for greater AI velocity and positive business impact.
Ready to get started and try it out for yourself? Watch this Databricks event to see it in action. You can read more about Databricks Model Serving and how to use it in the Databricks on AWS documentation and the Azure Databricks documentation. Learn more about data observability in the Unravel documentation.