
Table of Contents

Experts from Microsoft, WANdisco, and Unravel Data recently outlined a step-by-step playbook—utilizing a data-driven approach—for migrating and managing data applications in the cloud.
Unravel Data Co-Founder and CTO Shivnath Babu moderated a discussion with Microsoft Chief Architect Amit Agrawal and WANdisco CTO Paul Scottt-Murphy on how Microsoft, WANdisco, and Unravel complement each other is accelerating the migration of complex data applications like Hadoop to cloud environments like Azure.
Shivnath is an industry leader in making large-scale data platforms and distributed systems easy to manage. At Microsoft, Amit is responsible for driving cross-cloud solutions and is an expert in Hadoop migrations. Paul spearheads WANdisco’s “data-first strategy,” especially in how to migrate fast-changing and rapidly growing datasets to the cloud in a seamless fashion.
We’re all seeing how data workloads are moving to the cloud en masse. There are several reasons, probably higher business agility topping the list. Plus you get access to the latest and greatest modern software to power AI/ML initiatives. If you optimize properly, the cloud can be hugely cost-beneficial. And then there’s the issue of Cloudera stopping support for its older on-prem software.
But getting to the cloud is not easy. Time and time again, we hear how companies’ migration to the cloud goes over budget and behind schedule. Most enterprises have complex on-prem environments, which are hard to understand. Mapping them to the best cloud topology is even harder—especially when there isn’t enough talent available with the expertise to migrate workloads correctly. All too often, migration involves a lot of time-consuming, error-prone manual effort. And one of the bigger challenges is simply the lack of prioritization from the business.
During the webinar, the audience was asked, “What challenges have you faced during your cloud migration journey?” Nearly two-thirds responded with “complexity of my current environment,” followed by “finding people with the right skills.”

These challenges are exactly why Microsoft, WANdisco, and Unravel have created a framework to help you accelerate your migration to Azure.
Watch webinar
Hadoop Migration Framework
As enterprises build up their data environment over the years, it becomes increasingly difficult to understand what jobs are running and whether they’re optimized—especially for cost, as there’s a growing recognition that jobs which are not optimized can lead to cloud costs spiraling out of control very quickly—and then tie migration efforts to business priorities.
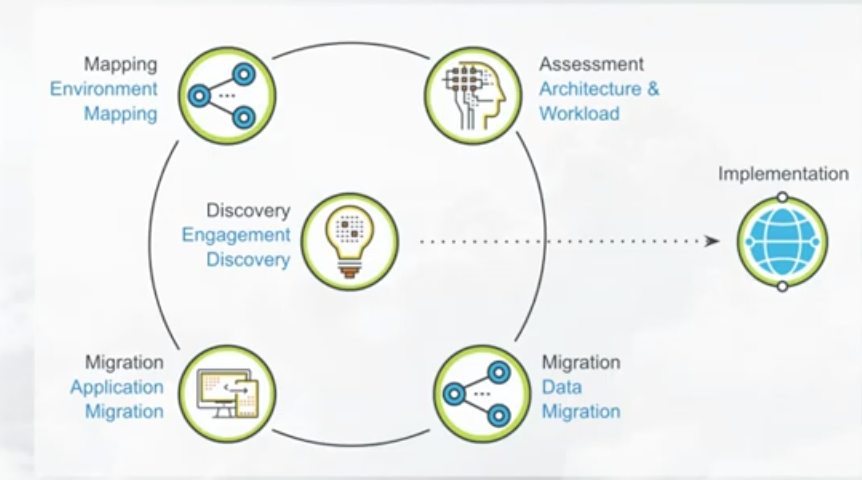
The Microsoft Azure framework for migrating complex on-prem data workloads to the cloud
Amit laid out the framework that Azure uses when first talking to customers about migration. It starts with an engagement discovery that basically “meets the customer where they are” to identify the starting point for the migration journey. Then they take a data-first approach by looking at four key areas:
- Environment mapping: This is where Unravel really helps by telling you exactly what kind of services you’re running, where they’re running, which queues they belong to, etc. This translates into a map of how to migrate into Azure, so you have the right TCO from the start. You have a blueprint of what things will look like in Azure and a step-by-step process of where to migrate your workloads.
- Application migration: With a one-to-one map of on-prem applications to cloud applications in place, Microsoft can give customers a clear sense of how, say, an end-of-life on-prem application can be retired in lieu of a modern application.
- Workload assessment: Usually customers want to “test the waters” by migrating over one or two workloads to Azure. They are naturally concerned about what their business-critical applications will look like in the cloud. So Microsoft does an end-to-end assessment of the workload to see where it fits in, what needs to be done, and thereby give both the business stakeholder and IT the peace of mind that their processes will not break during migration.
- Data migration: This is where WANdisco can be very powerful, with your current data estate migrated or replicated over to Azure and your data scientists starting to work on creating more use cases and delivering new insights that drive better business processes or new business streams.
Then, once all this is figured out, they determine what the business priorities are, what the customer goals are. Amit has found that this framework fits any and all customers and helps them realize value very quickly.

Data-first strategy vs. traditional approach to cloud migration
Data-First Strategy
A data-first strategy doesn’t mean you need to move your data before doing anything else, but it does mean that having data available in the cloud is critical to quickly gaining value from your target environment.
Without the data being available in some form, you can’t work with it or take advantage of the capabilities that a cloud environment like Azure offers.
A data-first migration differs from a traditional approach, which tends to be more application-centric—where entire sets of applications and their data in combination need to be moved before a hard cutover to use in the cloud environment.
As Paul Scott-Murphy from WANdisco explains, “That type of approach takes much longer to complete and doesn’t allow you to use data while a migration is under way. It also doesn’t allow you to continue to operate the source environment while you’re conducting a migration. So that may be well suited to smaller types of systems—transactional systems and online processing environments—but it’s typically not very well suited to the sort of information data sets and the work done against them from large-scale data platforms built around a data lake.
“So really what we’re saying here is that the migration of analytics infrastructure from data lake environments on premises like Hadoop and Spark and other distributed environments is extremely well suited to a data-first strategy, and what that strategy means is that your data become available for use in the cloud environment in as short a time as possible, really accelerating the pace with which you can leverage the value and giving you the ability to get faster outcomes from that data.
“The flexibility it offers in terms of automating the migration of your data sets and allowing you to continue operating those systems while the migration is underway is also really critical to the data-first migration approach.”
That’s why WANdisco developed its data-first strategy around four fundamental requirements:
1. The technology must efficiently handle arbitrary volumes of data. Data lakes can span potentially exabyte-scale data systems, and traditional tools for copying static information aren’t going to satisfy the needs of migrating data at scale.
2. You need a modern approach to support frequent and actively changing data. If you have data at scale, it is always changing—you’re ingesting that data set all the time, you’re constantly modifying information in your data lake.
3. You don’t want to suffer downtime in your business systems just for the purpose of migrating to the cloud. Incurring additional costs beyond the effort involved in migration is likely to be unacceptable to the business.
4. You need to validate or have a means of ensuring that your data migrated in full.
With those elements as the technical basis, WANdisco has developed the technology, LiveData Migrator for Azure, to support this approach to data-first migration. The approach that WANdisco technology enables with data-first migration is really central to getting the most out of your migration effort.
See case study
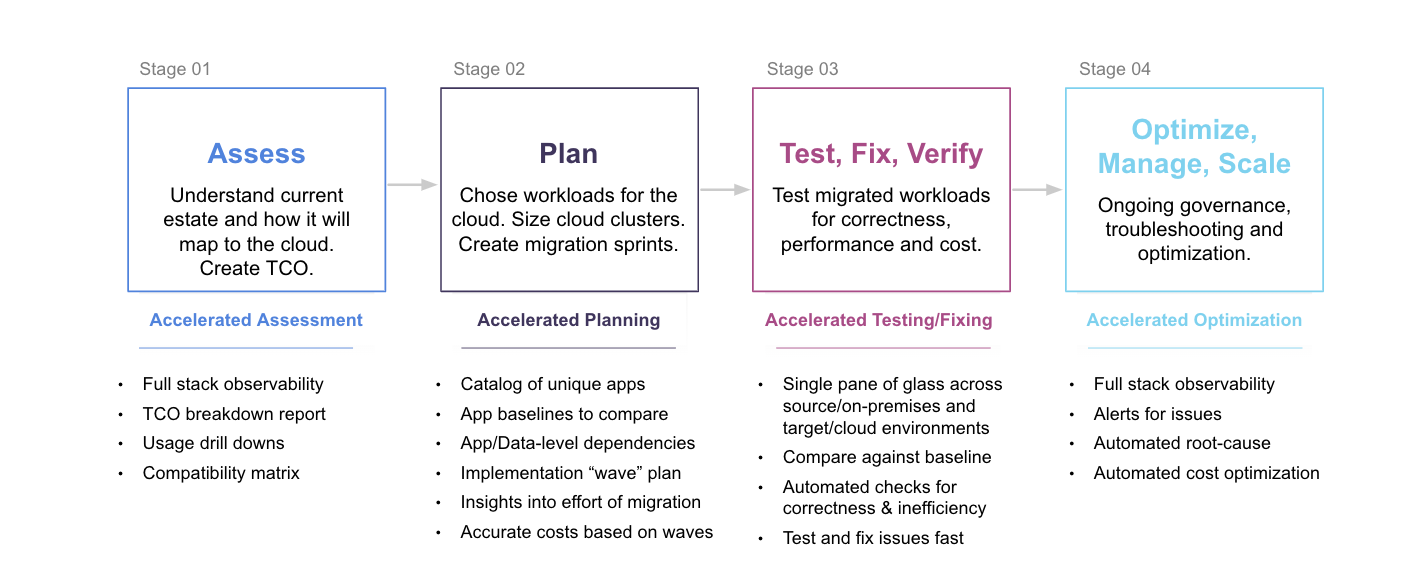
Unravel accelerates every stage of migration
How to Accelerate the Migration Journey
When teaming up with Microsoft and WANdisco, Unravel splits the entire migration into four stages:
1. Assess
This is really about assessing the current environment. Assessing a complex environment can take months—it’s not uncommon to see a 6-month assessment—which gets expensive and is often inaccurate about all the dependencies across all the apps and data and resources and pipelines. Identifying the intricate dependencies is critical to the next phase—we’ve seen how 80% of the time and effort in a migration can be just getting the dependencies right.
2. Plan
This is the most important stage. Because if the plan is flawed, with inaccurate or incomplete data, there is no way your migration will be done on time and within budget. It’s not unusual to see a migration have to be aborted partway through and then restarted.
3. Test, Fix, Verify
Usually the first thing you ask after a workload has migrated is, Is it correct? Are you getting the same or better performance that we got on-prem? And are you getting that performance at the right cost? Again, if you don’t get it right, the entire cost of migration can run significantly over budget.
4. Optimize, Manage, Scale
As more workloads come over to the cloud, scaling becomes a big issue. It can be a challenge to understand the entire environment and its cost, especially around governance. Because if you don’t bring in best practices and set up guardrails from the get-go, it can be very difficult to fix things later on. That can lead to low reliability, or maybe the clusters are auto-scaling and the expenses are much higher than they need to be—actually, a lot of things can go wrong.
Unravel can help with all of these challenges. And it helps by accelerating each stage. How can you accelerate assessment? Unravel automatically generates an X-ray of the complex on-prem environment, capturing all the dependencies and converting that information into a quick total cost of ownership analysis. That can be then used to justify and prioritize the business to actually move to the cloud pretty quickly. Then you can drill down from the high-level cost estimates into where the big bottlenecks are (and why).
This then feeds into the planning, where it’s really all about ensuring that the catalog, or inventory, of apps, data, and resources that has been built—along with all the dependencies that have been captured—is converted into a sprint-by-sprint plan for the migration.
As you go through these sprints, that’s where the testing, fixing, and verifying are done—especially getting a single pane of glass that can show the workloads as they are running on-prem and then the migrated counterparts on the cloud so that correctness, performance, and cost can be easily checked and verified against the baseline.
Then everything gets magnified as more and more apps are brought over. Unravel provides full-stack observability along with the ability to govern and fix problems. But most important, Unravel can help ensure that these problems in terms of performance, correctness, and cost never happen in the first place.
Unravel complements Microsoft and WANdisco along at each step of the new data-first cloud migration playbook.
Check out the entire New Cloud Migration Playbook webinar on demand.