







Press
- CI/CD
FinOps Metrics That Matter Register Now

FinOps Metrics That Matter Register Now



"We cut costs by 70% in the first 6 months."
HEAD OF DATA PLATFORM OPTIMIZATION Global Logistics Company

“Unravel cut our cloud data costs by 70% in six months—and keep them down.”
Learn More
“Equifax receives over 12 million online inquiries per day. Unravel has accelerated data product innovation and delivery.”
Learn More
“Unravel helped us improve the platform resiliency and availability multiple fold.”
Learn More












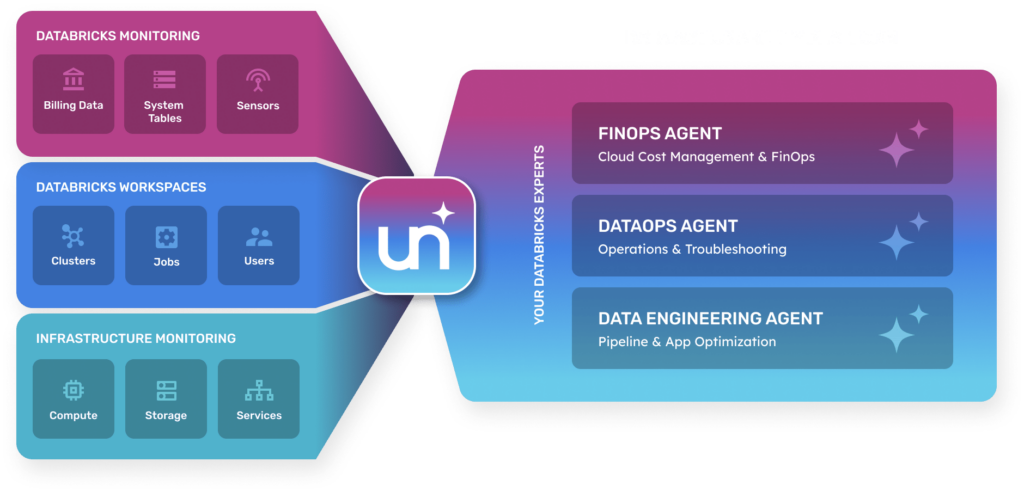
CLOUD COST MANAGEMENT & FINOPS SELF-GUIDED TOURS
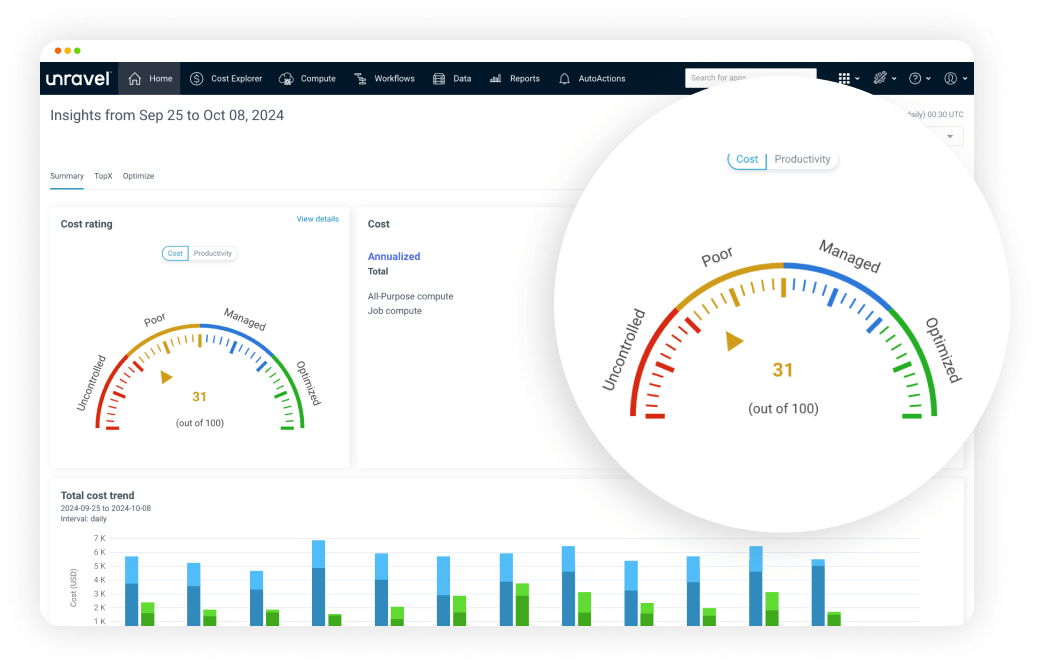
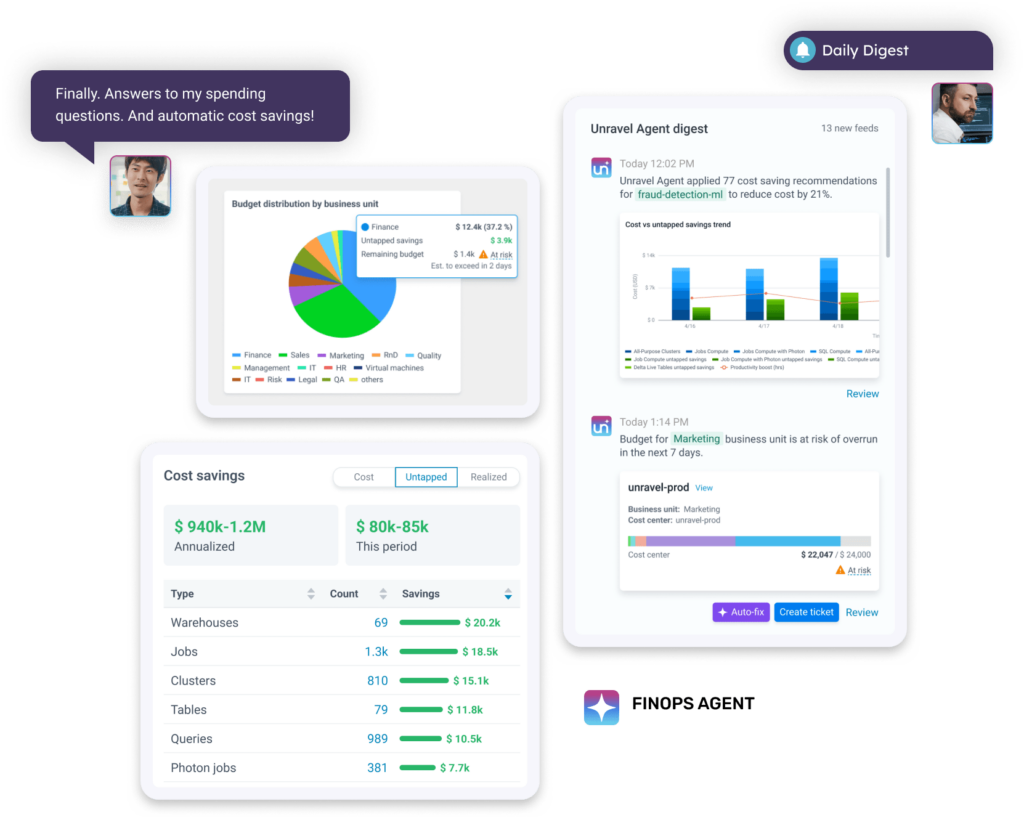
Get a bird's-eye view of productivity, cost and performance optimizations.
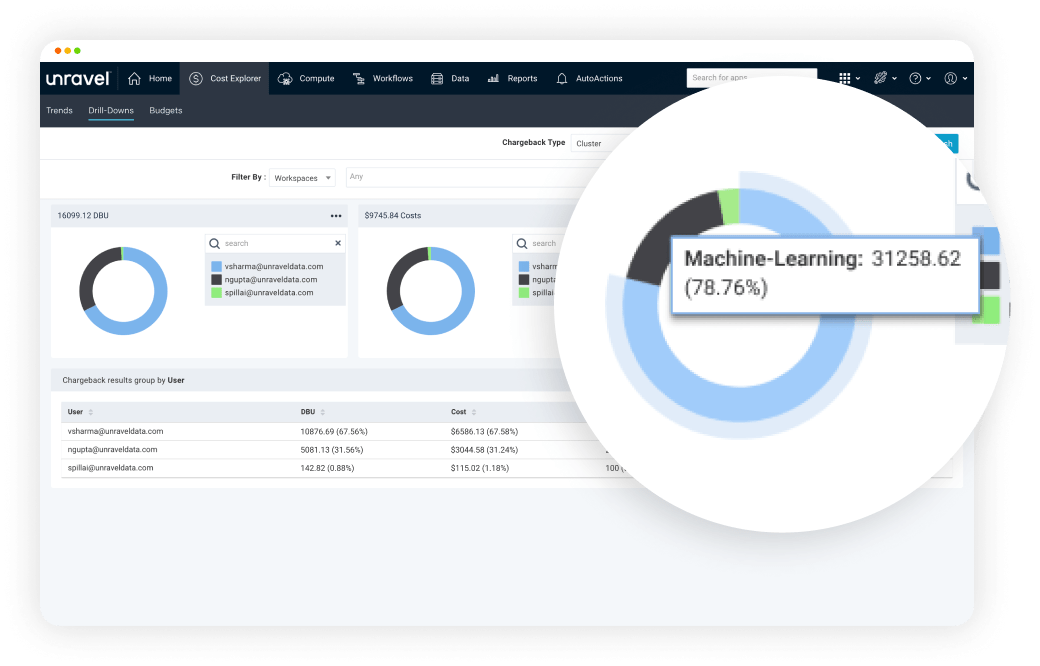
Assign cost with business context. Track overages. Get AI-driven cost-saving recommendations.
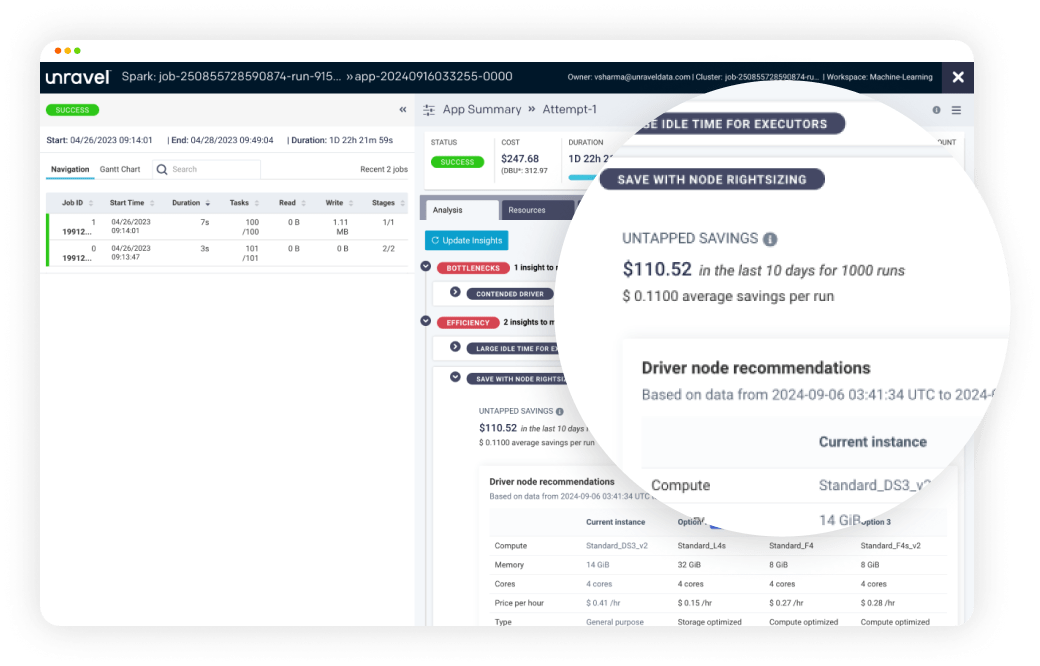
Quickly reduce spending at the cluster level with AI-driven cost-saving recommendations.
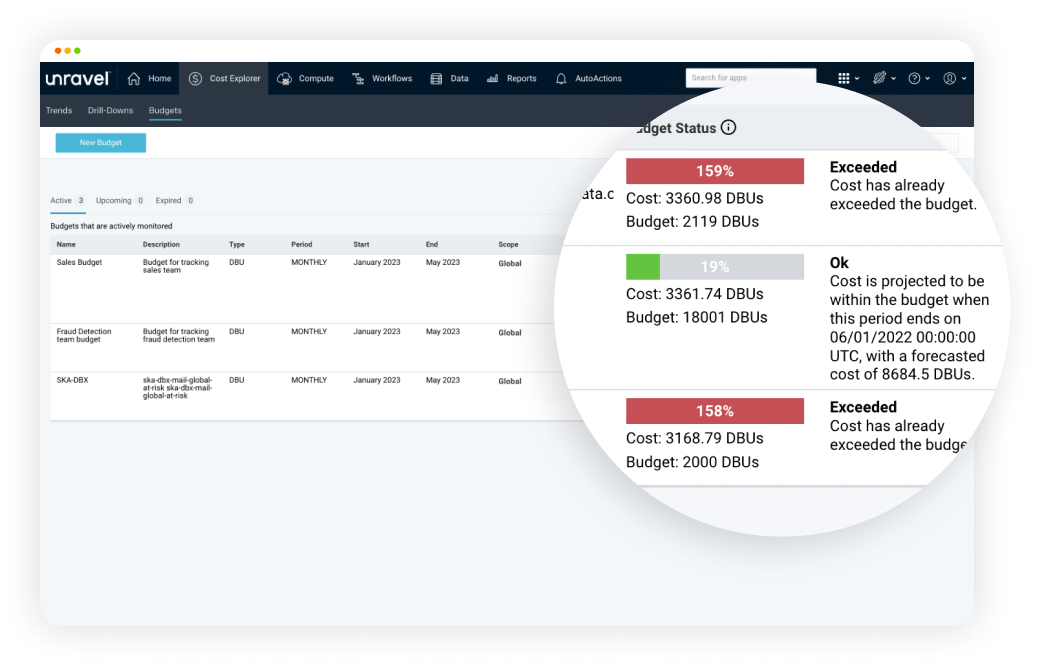
Track budgets vs. actual spending at a granular level and optimize costs with AI-driven recommendations.
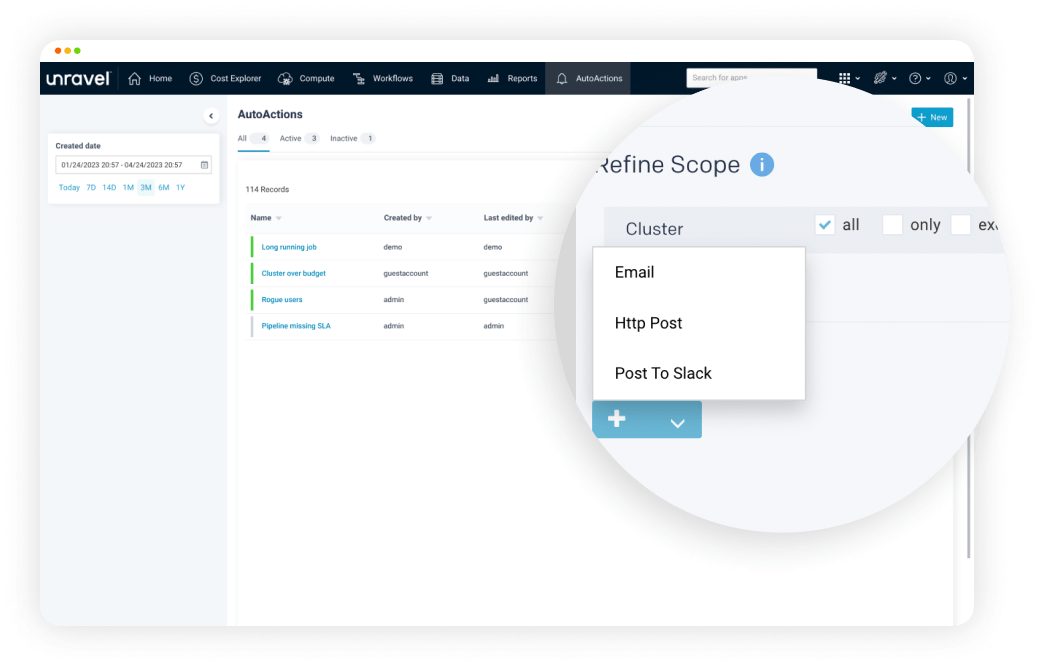
Create guardrails and keep budgets on track with automated oversight and real-time notifications.
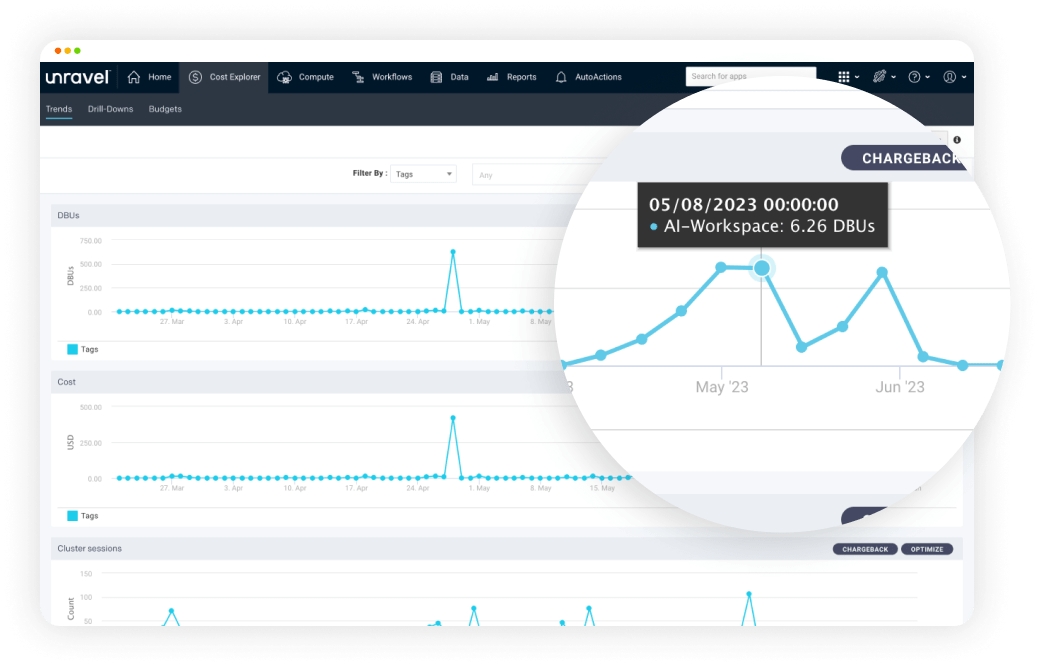
Accurately forecast cloud data spending with a data-driven view of consumption trends.
Get a bird's-eye view of productivity, cost and performance optimizations.
Assign cost with business context. Track overages. Get AI-driven cost-saving recommendations.
Quickly reduce spending at the cluster level with AI-driven cost-saving recommendations.
Track budgets vs. actual spending at a granular level and optimize costs with AI-driven recommendations.
Create guardrails and keep budgets on track with automated oversight and real-time notifications.
Accurately forecast cloud data spending with a data-driven view of consumption trends.
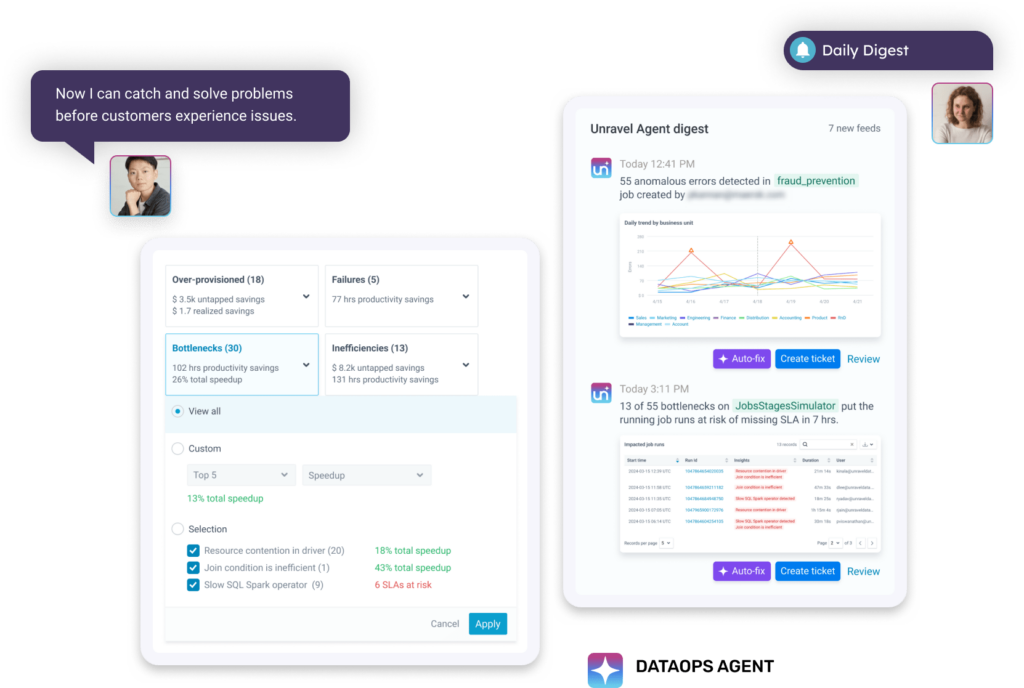
OPERATIONS & TROUBLESHOOTING SELF-GUIDED TOURS
Quickly reduce spending at the cluster level with AI-driven cost-saving recommendations.
Quickly reduce spending at the cluster level with AI-driven cost-saving recommendations.
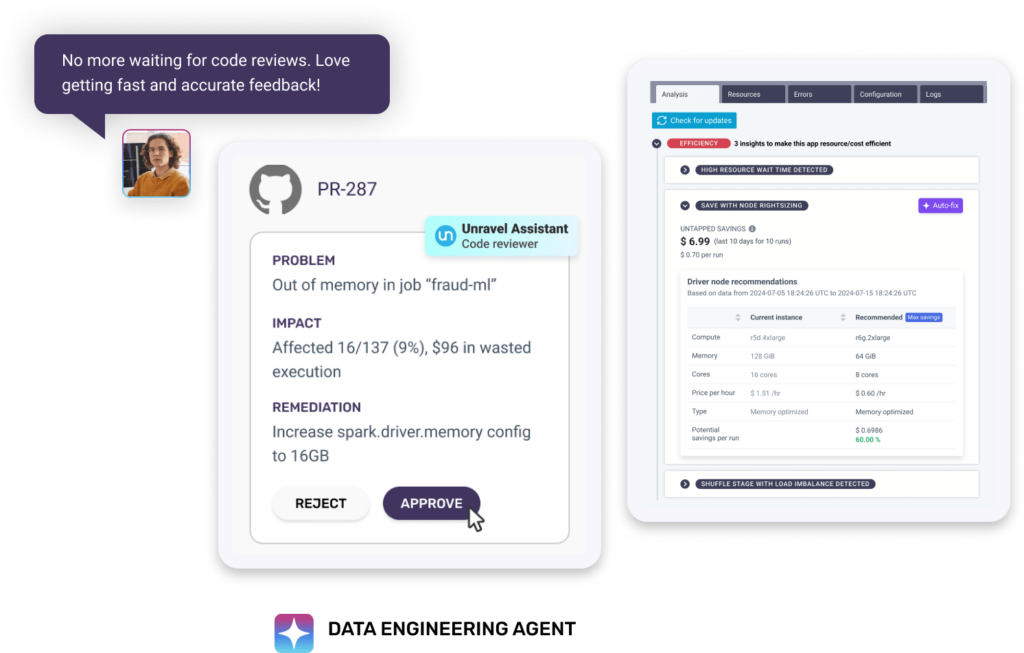
PIPELINE & APP OPTIMIZATION SELF-GUIDED TOURS
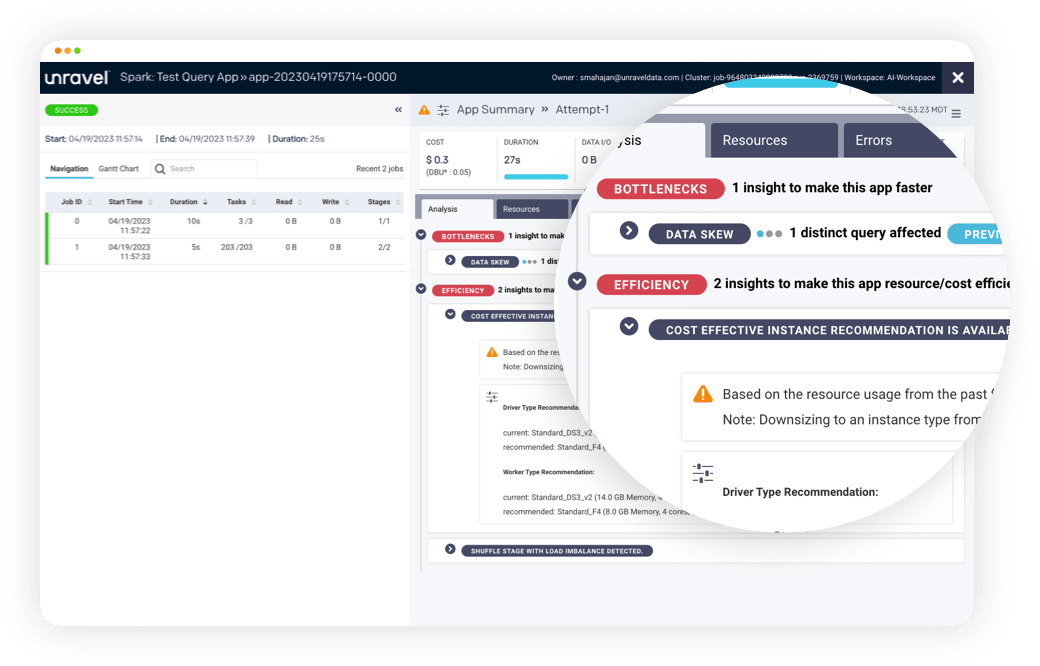
Quickly tune application performance and/or reduce costs with AI recommendations.
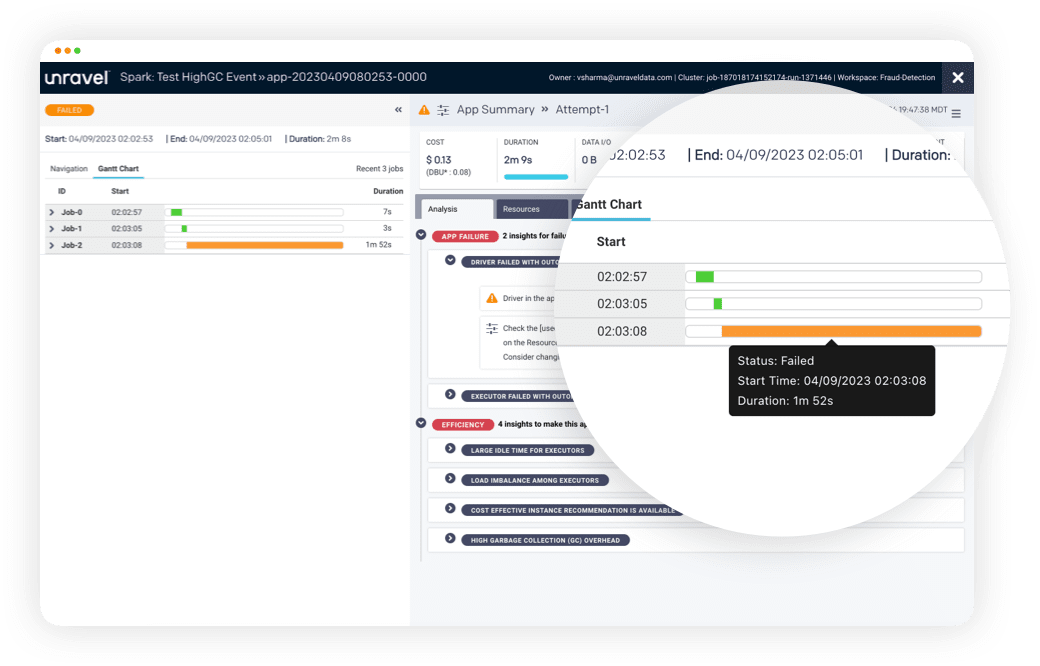
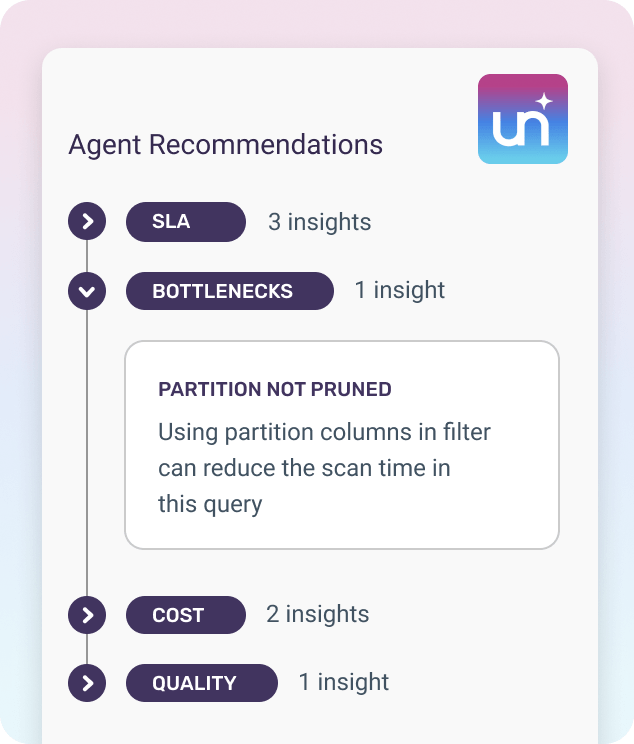
Quickly pinpoint where pipelines have bottlenecks and why they're missing SLAs.
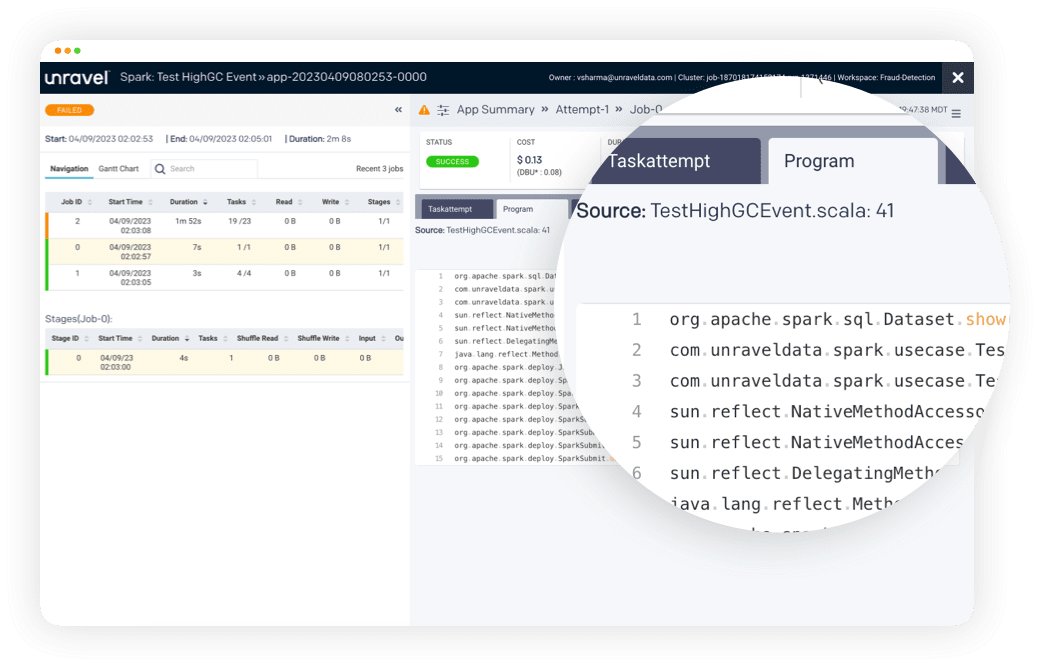
Quickly pinpoint exactly where, and why, application code is inefficient or failing in one easy-to-read view.
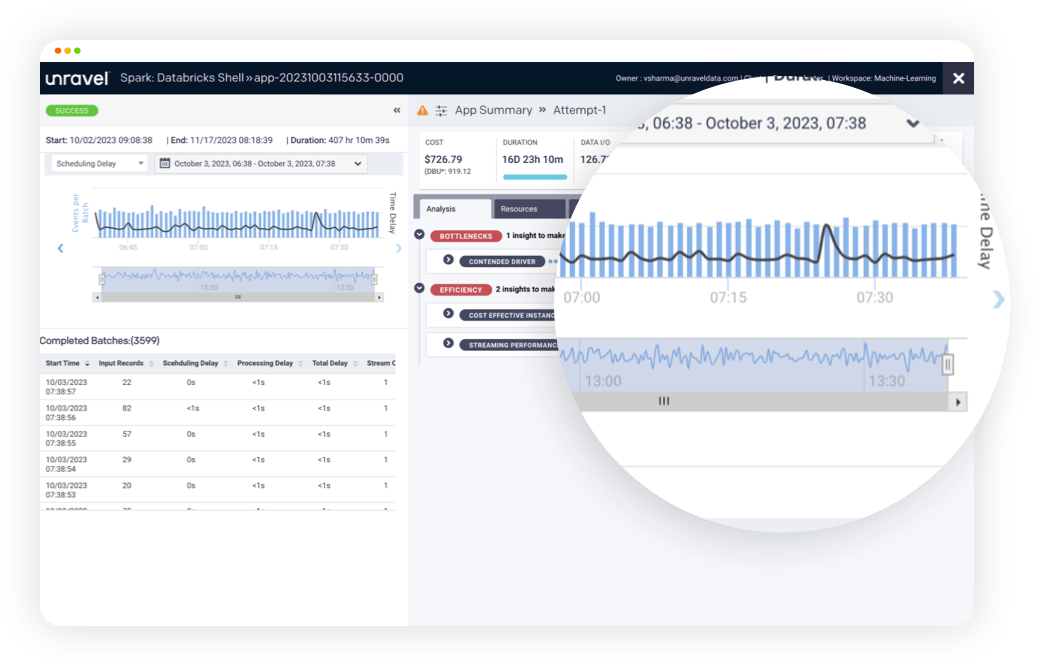
Keep your machine learning apps running smoothly using Unravel's AI-enabled observability.
Quickly tune application performance and/or reduce costs with AI recommendations.
Quickly pinpoint where pipelines have bottlenecks and why they're missing SLAs.
Quickly pinpoint exactly where, and why, application code is inefficient or failing in one easy-to-read view.
Keep your machine learning apps running smoothly using Unravel's AI-enabled observability.

No. Databricks Units (DBUs) are reference units of Databricks Lakehouse Platform capacity used to price and compare data workloads. DBU consumption depends on the underlying compute resources and the data volume processed. Cloud resources such as compute instances and cloud storage are priced separately. Databricks pricing is available for Amazon Web Services (AWS), Microsoft Azure, and Google Cloud Platform (GCP). You can estimate costs online for Databricks on AWS, Azure Databricks, and Databricks on Google Cloud, then add estimated cloud compute and storage costs with the AWS Pricing Calculator, the Azure pricing calculator, and the Google Cloud pricing calculator.
Cost 360 for Databricks provides trends and chargeback by app, user, department, project, business unit, queue, cluster, or instance. You can see a cost breakdown for Databricks clusters in real time, including related services such as DBUs and VMs for each configured Databricks account on the Databricks Cost Chargeback details tab. In addition, you get a holistic view of your cluster, including resource utilization, chargeback, and instance health, with automated AI-based cluster cost-saving recommendations and suggestions.
Databricks offers general tips and settings for certain scenarios, for example, auto optimize to compact small files. Unravel provides recommendations, efficiency insights, and tuning suggestions on the Applications page and the Jobs tab. With a single Unravel instance, you can monitor all your clusters, across all instances, and workspaces in Databricks to speed up your applications, improve your resource utilization, and identify and resolve application problems.
Yes. Unravel’s CI/CD integration for Databricks is language-agnostic. It seamlessly integrates with popular programming languages such as SQL, Python, Scala, and Java.
Yes. Unravel’s CI/CD integration for Databricks supports both Azure DevOps and GitHub. You have the flexibility to choose the platform that best suits your team’s needs.
Yes. With Unravel’s CI/CD integration for Databricks, you gain access to comprehensive metrics and AI-powered insights about your pipelines’ performance. You can identify and quickly resolve bottlenecks, improve resource efficiency, optimize code, and make data-driven decisions.
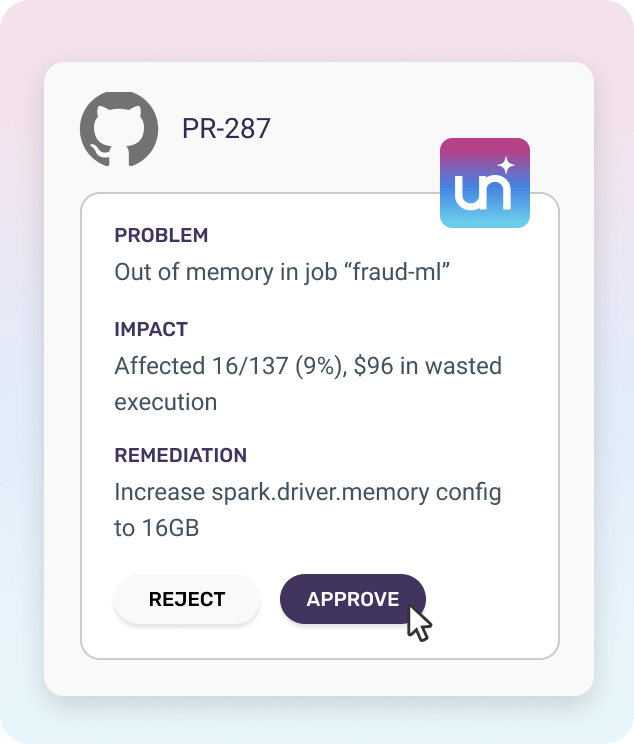
Yes. Unravel allows you to tailor the PR review process according to your specific requirements. You can define custom rules, set thresholds for performance metrics, and establish guidelines to ensure code quality.
Yes. Unravel’s CI/CD integration for Databricks seamlessly integrates with popular automated testing frameworks. You can incorporate unit tests, integration tests, and regression tests into your pipeline to ensure the reliability of your code.
Real-time monitoring and alerting with Databricks Overwatch requires a time-series database. Databricks refreshes your billable usage data about every 24 hours and AWS Cost and Usage Reports are updated once a day in comma-separated value (CSV) format. Since Cost Explorer includes usage and costs of other services, you should tag your Databricks resources and you may consider creating custom tags to get granular reporting on your Databricks cluster resource usage. Unravel simplifies this process with Cost 360 for Databricks to provide full cost observability, budgeting, forecasting, and optimization in near real time. Cost 360 includes granular details about the user, team, data workload, usage type, data job, data application, compute, and resources consumed to execute each data application. In addition, Cost 360 provides insights and recommendations to optimize clusters and jobs as well as estimated cost improvements to prioritize workload optimization.
At the FinOps Crawl phase, the data will be less granular. You may start at the cloud provider and service level. In the Walk phase, you’ll want additional granularity to go into the application level. If FinOps data is only available at the cluster or infrastructure level, you may face challenges with allocation. In the Run phase, you may need to get to the user, project, and job level.
Data teams spend most of their time preparing data—data aggregation, cleansing, deduplication, synchronizing and standardizing data, ensuring data quality, timeliness, and accuracy, etc.—rather than actually delivering insights from analytics. Everybody needs to be working off a “single source of truth” to break down silos, enable collaboration, eliminate finger-pointing, and empower more self-service. Although the goal is to prevent data quality issues, assessing and improving data quality typically begins with monitoring and observability, detecting anomalies, and analyzing root causes of those anomalies.
Databricks collects monitoring and operational data in the form of logs, metrics, and events for your Databricks job flows. Databricks metrics can be used to detect basic conditions such as idle clusters and nodes or clusters that run out of storage. Troubleshooting slow clusters and failed jobs involves a number of steps such as gathering data and digging into log files. Data application performance tuning, root cause analysis, usage forecasting, and data quality checks require additional tools and data sources. Unravel accelerates the troubleshooting process by creating a data model using metadata from your applications, clusters, resources, users, and configuration settings, then applying predictive analytics and machine learning to provide recommendations and automatically tune your Databricks clusters.
Virtual Private Cloud (VPC) peering enables you to create a network connection between Databricks clusters and your AWS resources, even across regions, enabling you to route traffic between them using private IP addresses. For example, if you are running both an Unravel EC2 instance and a Databricks cluster in the us-east-1 region but configured with different VPC and subnet, there is no network access between the Unravel EC2 instance and Databricks cluster by default. To enable network access, you can set up VPC peering to connect Databricks to your EC2 Unravel instance.
Unravel provides granular Insights, recommendations, and automation for before, during and after your Spark, Hadoop and data migration to Databricks.
Get granular chargeback and cost optimization for your Databricks workloads. Unravel for Databricks is a complete data observability platform to help you tune, troubleshoot, cost-optimize, and ensure data quality on Databricks. Unravel provides AI-powered recommendations and automated actions to enable intelligent optimization of big data pipelines and applications.
Many enterprises are facing this exact situation, experiencing performance and cost issues migrating on-premises workloads to Databricks. On-prem workloads are naturally limited in terms of cost due to the physical constraints of their data center, but costs can suddenly grow on the cloud. Enterprises who have successfully migrated to Databricks start by optimizing jobs before moving them to the cloud to ensure they can predict the spend and performance.
Azure Databricks offers optimization suggestions and troubleshooting tips for certain scenarios, for example, auto optimize to compact small files. Unravel provides recommendations, efficiency insights, and tuning suggestions on the Applications page and the Jobs tab. With a single Unravel instance, you can monitor all your clusters, across all instances, and workspaces in Azure Databricks to speed up your applications, improve your resource utilization, and identify and resolve application problems.
Azure Databricks collects monitoring and operational data in the form of logs, metrics, and monitoring for your Azure Databricks job flows. Azure Databricks metrics can be used to detect basic conditions such as idle clusters and nodes or clusters that run out of storage. Troubleshooting slow clusters and failed jobs involves a number of steps such as gathering data and digging into log files. Data application performance tuning, root cause analysis, usage forecasting, and data quality checks require additional tools and data sources. Unravel accelerates the troubleshooting process by creating a data model using metadata from your applications, clusters, resources, users, and configuration settings, then applying predictive analytics and machine learning to provide recommendations and automatically tune your Azure Databricks clusters.
The main difference between many code generation products currently available is that they are typically based on static code analysis, while Unravel’s AI Insights Engine uses dynamic code analysis–meaning that its review of code and SQL is based on more than just the code itself, but also the data layout, table structure, partitioning, and other metadata. Unravel also analyzes your code’s runtime performance and efficiency to enhance recommendations.
No, it is not mandatory, but very useful if possible. Azure bill integration unlocks the full potential of Unravel’s cost analysis insights and reports. This integration ensures that the insights and reports obtained are as accurate and comprehensive as possible.
Unravel enables AI-driven innovation with Databricks such as fraud detection. Unravel is committed to security and focused on keeping our clients and their data safe. Unravel is SOC 2-compliant, and has earned a Service Organization Control (SOC) 2, Type II certification.
Unravel doesn’t orchestrate Databricks Workflows but uses AI to improve performance, productivity and cost efficiency of your Databricks jobs. Unravel’s AI Agents for Databricks provide insights and recommendations for optimizing Databricks jobs. Simply ask questions in plain language to identify areas for improvement and potential cost savings. You can ask specific questions about the insights, recommendations, or performance metrics of your Databricks jobs that run on job compute clusters.
Virtual network (VNET) peering enables you to create a network connection between Azure Databricks clusters and your Azure resources, even across regions, enabling you to route traffic between them using private IP addresses. For example, if you are running both an Unravel VM and Azure Databricks cluster in the East US region but configured with different VNET and subnet, there is no network access between the Unravel VM and Databricks cluster by default. To enable network access, you can set up VNET peering between your Azure Databricks master node and your Unravel VM.