

Table of Contents
Databricks recently hosted the Data + AI Summit 2022, attended by 5,000 people in person in San Francisco and some 60,000 virtually. Billed as the world’s largest data and AI conference, the event featured over 250 presentations from dozens of speakers, training sessions, and four keynote presentations.
Databricks made a slew of announcements falling into two buckets: enhancements to open-source technologies underpinning the Databricks platform, and previews, enhancements, and GA releases related to its proprietary capabilities. Day 1 focused on data engineering announcements, day 2 on ML announcements.
There was obviously a lot to take in, so here are just three takeaways from one attendee’s perspective.
Convergence of Data Analytics and ML
The predominant overarching (or underlying, depending on how you look at it) theme running as a red thread throughout all the presentations was the convergence of data analytics and ML. It’s well known how the “big boys” like Amazon, Google, Facebook, Netflix, Apple, and Microsoft have driven disruptive innovation through data, analytics, and AI. But now more and more enterprises are doing the same thing.
In his opening keynote presentation, Databricks Co-Founder and CEO Ali Ghodshi expressed this trend as the process of moving to the right-hand side of the Data Maturity Curve, moving from hindsight to foresight.
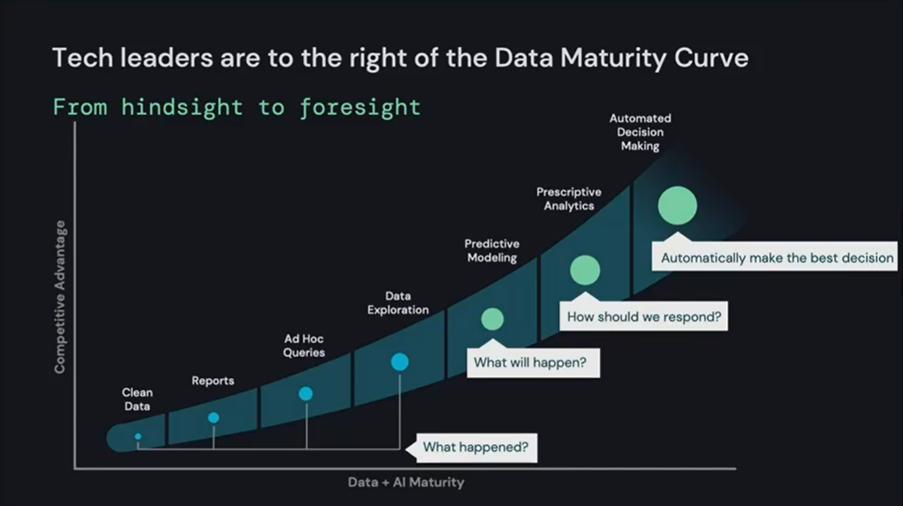
However, today most companies are not on the right-hand side of the curve. They are still struggling to find success at scale. Ghodshi says the big reason is that there’s a technology divide between two incompatible architectures that’s getting in the way. On one side are the data warehouse and BI tools for analysts; on the other, data lakes and AI technologies for data scientists. You wind up with disjointed and duplicative data silos, incompatible security and governance models, and incomplete support for use cases.
Bridging this chasm—where you get the best of both worlds—is of course the whole idea behind the Databricks lakehouse paradigm. But it wasn’t just Databricks who was talking about this convergence of data analytics and ML. Companies as diverse as John Deere, Intuit, Adobe, Nasdaq, Nike, and Akamai were saying the same thing. The future of data is AI/ML, and moving to the right-hand side of the curve is crucial for a better competitive advantage.
Databricks Delta Lake goes fully open source
Probably the most warmly received announcement was that Databricks is open-sourcing its Delta Lake APIs as part of its Delta Lake 2.0 release. Further, Databricks will contribute all its proprietary Delta Lake features and enhancements. This is big—while Databricks initially launched its lakehouse platform as open source back in 2019, many of its subsequent features were proprietary additions available only to its customers.
Download Unravel for Databricks data sheet
Databricks cost optimization + Unravel
A healthy number of the 5,000 in-person attendees swung by the Unravel booth to discuss its DataOps observability platform. Some were interested in how Unravel accelerates migration of on-prem Hadoop clusters to the Databricks platform. Others were interested in how its vendor-agnostic automated troubleshooting and AI-enabled optimization recommendations could benefit teams already on Databricks. But the #1 topic of conversation was around cost optimization for Databricks.
Specifically, these Databricks customers are realizing the business value of the platform and are looking to expand their usage. But they are concerned about running up unnecessary costs—whether it was FinOps people or data team leaders looking for ways to govern costs with greater accuracy, Operations personnel who had uncovered occurrences of jobs where someone had requested oversized configurations, or data engineers who wanted to find out how to right-size their resource requests. Everybody wanted to discover a data-driven approach to optimizing jobs for cost. They all said the same thing, one way or another: the powers-that-be don’t mind spending money on Databricks, given the value it delivers; what they hate is spending more than they have to.
And this is something Databricks as a company appreciates from a business perspective. They want customers to be happy and successful—if customers have confidence that they’re spending only as much as absolutely necessary, then they’ll embrace increased usage without batting an eye.
This is where Unravel really stands out from the competition. Its deep observability intelligence understands how many and what size resources are actually needed, compares that to the configuration settings the user requested, and comes back with a crisp, precise recommendation on exactly what changes to make to optimize for cost—at either the job or cluster level. These AI recommendations are generated automatically, waiting for you at any number of dashboards or views within Unravel. Cost-optimization recommendations let you cut to the chase with literally just one click.
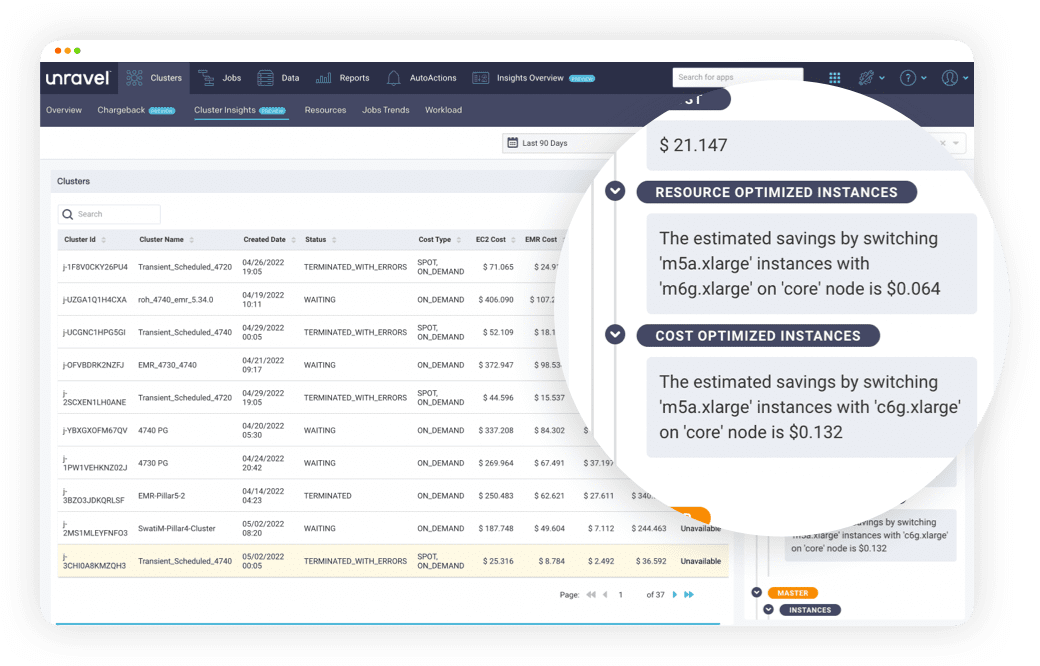
Check out this short interactive demo (takes about 90 seconds) to see Unravel’s Job-Level AI Recommendations capability or this one to see its Automated Cloud Cluster Optimization feature.