Data Observability for Snowflake Register

Data Observability for Snowflake Register
Unravel’s purpose-built AI data observability and FinOps for Databricks, Snowflake, BigQuery, and other modern data stacks provides granular visibility for cost allocation, metadata correlation for data quality and reliability, and AI-powered insights for data performance management. Unravel provides granular visibility into your data infrastructure, configuration, layout/partitioning, and code to achieve speed and scale through performance and efficiency.
Four challenges create friction and resistance for organizations as the scale and complexity of data and AI pipelines increase. Unravel helps you tackle these challenges so you can go faster and gain a competitive advantage.

A lack of production-ready data pipelines is the second-most-cited reason for AI project failure. Unravel enables you to create new apps 3x faster with AI insights that provide detailed actions to improve code, SQL, partitioning, and infrastructure before deploying to production.

Limited budgets, talent shortages, and time required to upskill employees are the biggest barriers to AI strategy adoption. Unravel’s purpose-built AI provides insights in real time at the job, user, and workgroup levels to help you improve cost allocation and workload efficiency.
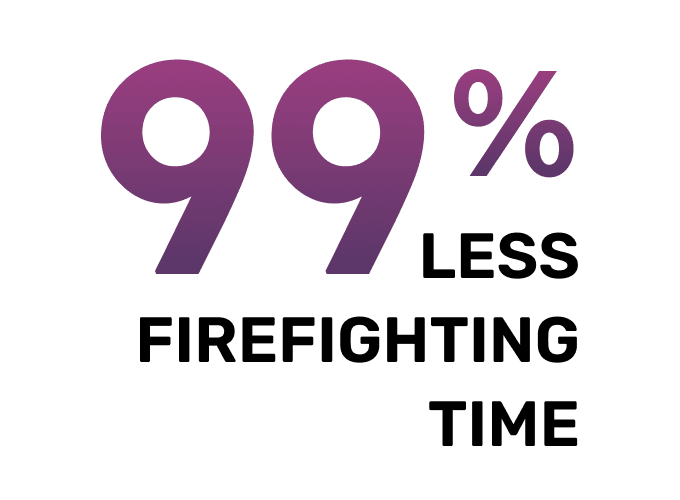
As data and AI pipelines become more complex, the time required for root cause analysis increases. Unravel helps data teams spend less time troubleshooting and tuning performance with purpose-built AI that provides an “expert in a box” to enable all skill levels to be proficient.

Sudden spikes in data volumes, new analytics use cases, and soaring cloud prices disrupt financial operations. Unravel’s purpose-built AI enables fine-grained budgeting and forecasting. Automated guardrails prevent accidental overages from runaway jobs and non-compliant workloads.

AI isn’t new to Unravel. We’ve had it since the beginning, automating tasks for data teams over the last 10 years after observing more than 50 million data pipelines and queries. Every data platform is unique, so you need AI that understands your specific data platform. Unravel’s ML models are trained for each specific platform—across a wide variety of workloads to provide your team accurate insights.
At the core of Unravel Data’s platform is its AI-powered Insights Engine, which has been trained to understand all the intricacies and complexities of modern data platforms, configuration, code, and the supporting infrastructure.
Unravel collects comprehensive metadata that’s specific to each data platform. So you have visibility that is very specific to your cloud data platform about who’s using what. All the way down to the jobs, service, user, application level. This deep visibility into the metadata from your specific data platform is the foundation for Unravel’s internal model to correlate all of the details in a way that is actionable and enables optimization at every level.
That’s where Unravel’s AI and machine learning come in. Based on your data platform’s unique configuration and usage patterns, Unravel’s AI-powered Insights Engine correlates the metadata about table and partition access metrics, source code, and dependencies for each stage of your data pipelines. Unravel delivers insights for each of the components that matter to your data teams.
Unravel helps you visualize and understand all of the interrelationships within your data stack, such as degree of parallelism, resource contention, dependencies, and data lineage. All of this information is presented in views that are relevant to how data teams need to understand that information to operate the data platform.
Unravel’s AI can analyze queries and code written in a wide variety of languages—SQL, Python, Java, Scala—to help uncover anti-patterns early in the data application development lifecycle.






















