

Table of Contents
In a recent webinar, Functional (& Funny) Strategies for Modern Data Architecture, we combined comedy and practical strategies for migrating from Hadoop to AWS.
Unravel Co-Founder and CTO Shivnath Babu moderated a discussion with AWS Principal Architect, Global Specialty Practice, Dipankar Ghosal and WANdisco CTO Paul Scott-Murphy. Here are some of the key takeaways from the event.
Hadoop migration challenges
Business computing workloads are moving to the cloud en masse to achieve greater business agility, access to modern technology, and reduce operational costs. But identifying what you have running, understanding how it all works together, and mapping it to a cloud topology is extremely difficult when you have hundreds, if not thousands, of data pipelines and are dealing with tens of thousands of data sets.
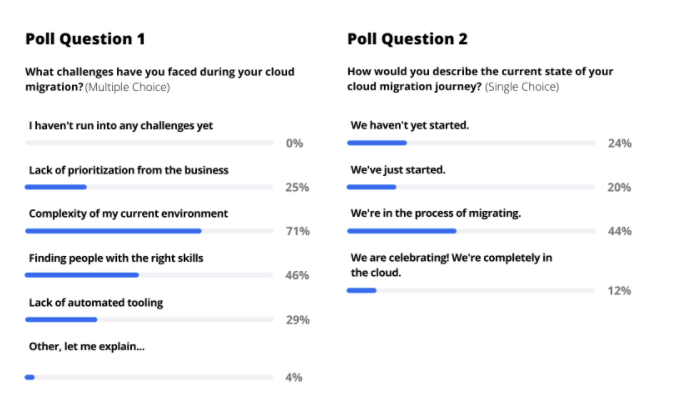
We asked attendees what their top challenges have been during cloud migration and how they would describe the current state of their cloud journey. Not surprisingly, the complexity of their environment was the #1 challenge (71%), followed by the “talent gap” (finding people with the right skills).
The unfortunate truth is that most cloud migrations run over time and over budget. However, when done right, moving to the cloud can realize spectacular results.
How AWS approaches migration
Dipankar talked about translating a data strategy into a data architecture, emphasizing that the data architecture must be forward-looking: it must be able to scale in terms of both size and complexity, with the flexibility to accommodate polyglot access. That’s why AWS does not recommend a one-size-fits-all approach, as it eventually leads to compromise. With that in mind, he talked about different strategies for migration.
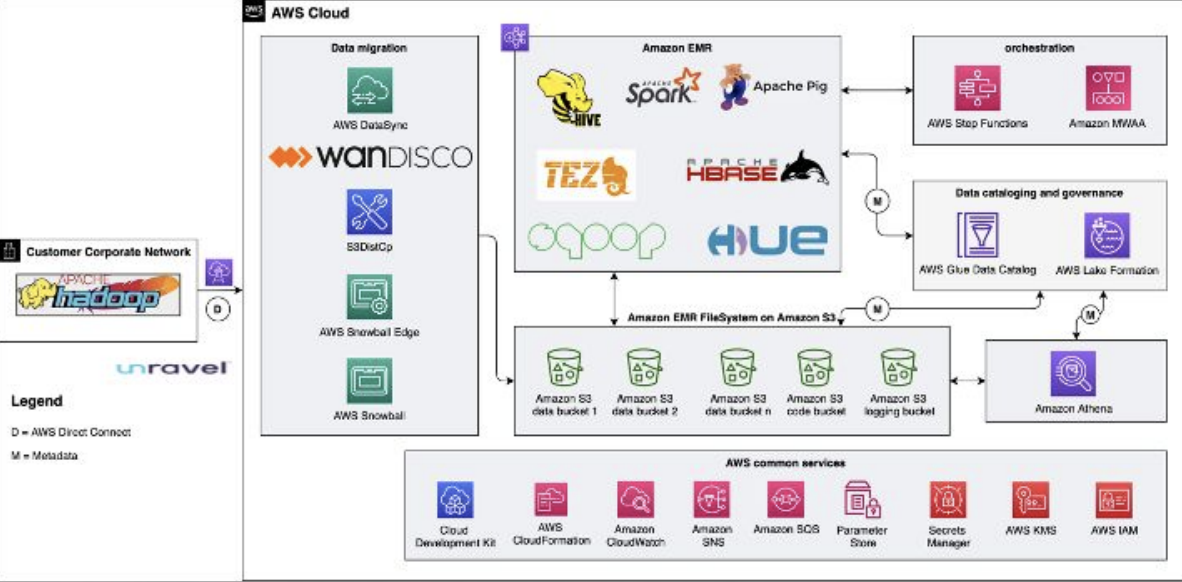
Hadoop to Amazon EMR Migration Reference Architecture
He recommends a data-first strategy for complex environments where it’s a challenge to find the right owners to define why the system is in place. Plus, he said, “At the same time, it gives the business the data availability on the cloud, so that they can start consuming the data right away.”
The other approach is a workload-first strategy, which is favored when migrating a relatively specialized part of the business that needs to be refactored (e.g., Pig to Spark).
He wrapped up with a process with different “swim lanes where every persona has skin in the game for a migration to be successful.”
Why a data-first strategy?
Paul followed up with a deeper dive into a data-first strategy. Specifically, he pointed out that in a cloud migration, “people are unfamiliar with what it takes to move their data at scale to the cloud. They’re typically doing this for the first time, it’s a novel experience for them. So traditional approaches to copying data, moving data, or planning a migration between environments may not be applicable.” The traditional lift-and-shift application-first approach is not well suited to the type of architecture in a big data migration to the cloud.

Paul said that the WANdisco data-first strategy looks at things from three perspectives:
- Performance: Obviously moving data to the cloud faster is important so you can start taking advantage of a platform like AWS sooner. You need technology that supports the migration of large-scale data and allows you to continue to use it while migration is under way. There cannot be any downtime or business interruption.
- Predictability: You need to be able to determine when data migration is complete and plan for workload migration around it.
- Automation: Make the data migration as straightforward and simple as possible, to give you faster time to insight, to give you the flexibility required to migrate your workloads efficiently, and to optimize workloads effectively.
How Unravel helps before, during, and after migration
Shivnath went through the pitfalls encountered at each stage of a typical migration to AWS (assess; plan; test/fix/verify; optimize, manage, scale). He pointed out that it all starts with careful and accurate planning, then continuous optimization to make sure things don’t go off the rails as more and more workloads migrate over.
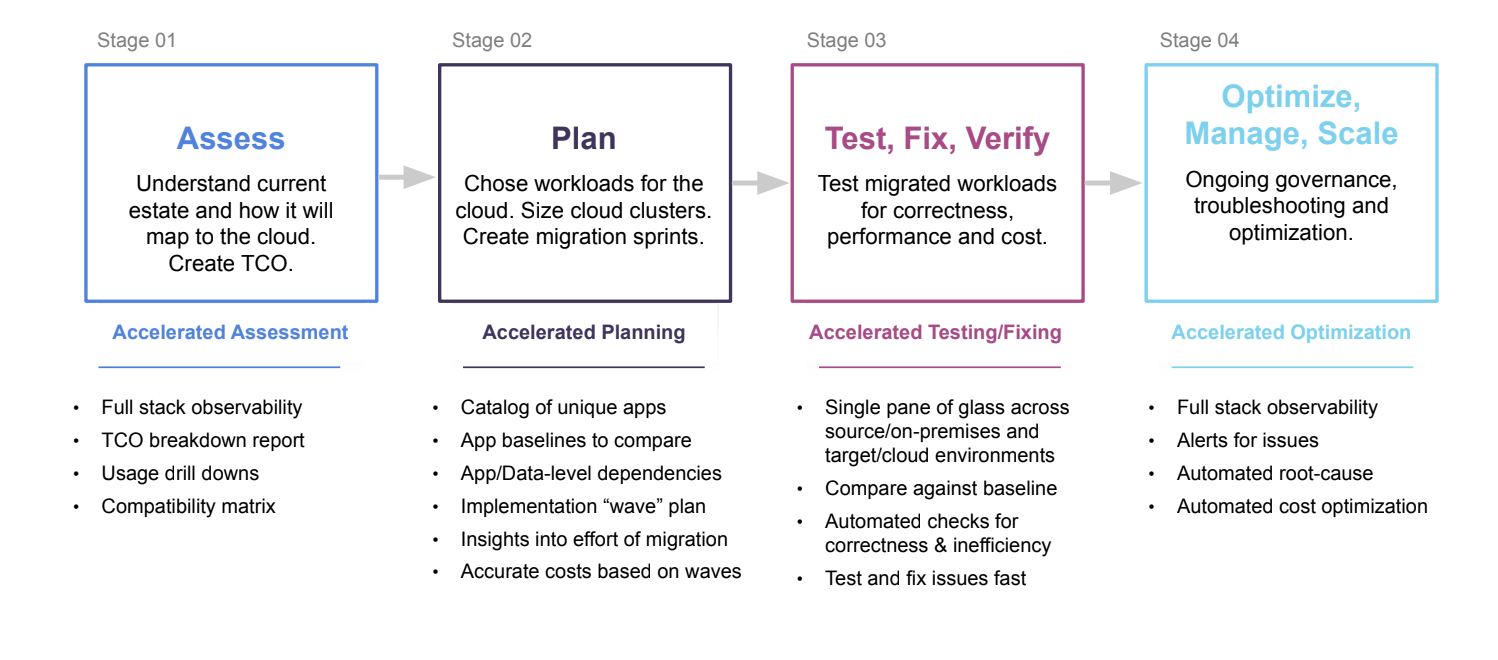
And to plan properly, you need to assess what is a very complex environment. All too often, this is a highly manual, expensive, and error-filled exercise. Unravel’s full-stack observability collects, correlates, and contextualizes everything that’s running in your Hadoop environment, including identifying all the dependencies for each application and pipeline.
Then once you have this complete application catalog, with baselines to compare against after workloads move to the cloud, Unravel generates a wave plan for migration. Having such accurate and complete data-based information is crucial to formulating your plan. Usually when migrations go off schedule and over budget, it’s because the original plan itself was inaccurate.
Then after workloads migrate, Unravel provides deep insights into the correctness, performance, and cost. Performance inefficiencies and over-provisioned resources are identified automatically, with AI-driven recommendations on exactly what to fix and how.
As more workloads migrate, Unravel empowers you to apply policy-based governance and automated alerts and remediation so you can manage, troubleshoot, and optimize at scale.
Case study: GoDaddy
The Unravel-WANdisco-Amazon partnership has proven success in migrating a Hadoop environment to EMR. GoDaddy had to move petabytes of actively changing “live” data when the business depends on the continued operation of applications in the cluster and access to its data. They had to move an 800-node Hadoop cluster with 2.5PB of customer data that was growing by more than 4TB every day. The initial (pre-Unravel) manual assessment took several weeks and proved incomplete: only 300 scripts were discovered, whereas Unravel identified over 800.
GoDaddy estimated that its lift-and-shift migration operating costs would cost $7 million, but Unravel AI optimization capabilities identified savings that brought down the cloud costs to $2.9 million. Using WANdisco’s data-first strategy, GoDaddy was able to complete its migration process on time and under budget while maintaining normal business operations at all times.
Q&A
The webinar wrapped up with a lively Q&A session where attendees asked questions such as:
- We’re moving from on-premises Oracle to AWS. What would be the best strategy?
- What kind of help can AWS provide in making data migration decisions?
- What is your DataOps strategy for cloud migration?
- How do you handle governance in the cloud vs. on-premises?
To hear our experts’ specific individual responses to these questions as well as the full presentation, click here to get the webinar on demand (no form to fill out!)