

This blog provides some best practices for how to use Unravel to tackle issues of data skew and partitioning for Spark applications. In Spark, it’s very important that the partitions of an RDD are aligned with the number of available tasks. Spark assigns one task per partition and each core can process one task at a time.
By default, the number of partitions is set to the total number of cores on all the nodes hosting executors. Having too few partitions leads to less concurrency, processing skew, and improper resource utilization, whereas having too many leads to low throughput and high task scheduling overhead.
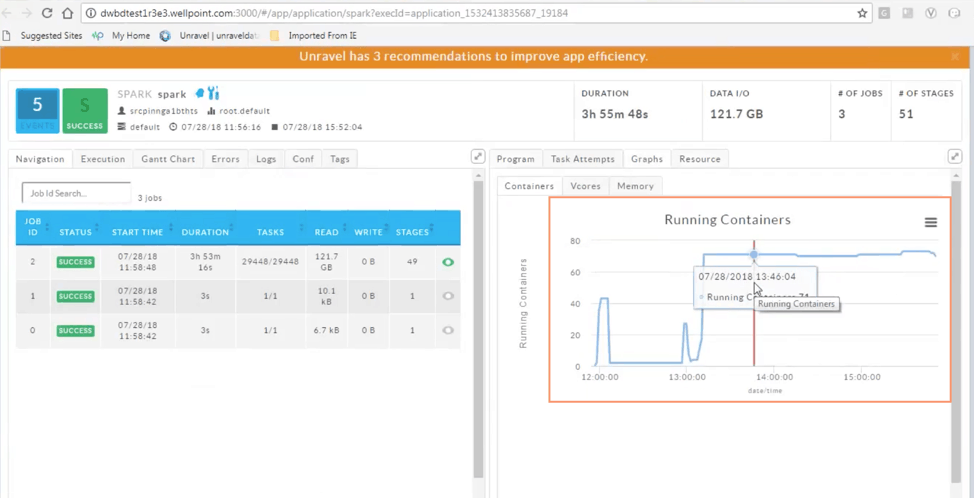
The first step in tuning a Spark application is to identify the stages which represents bottlenecks in the execution. In Unravel, this can be done easily by using the Gantt Chart view of the app’s execution. We can see at a glance that there is a longer-running stage:
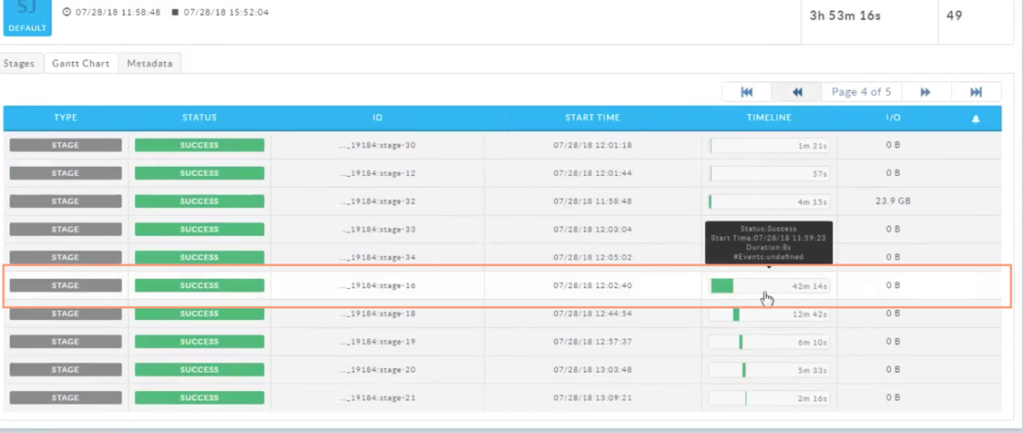
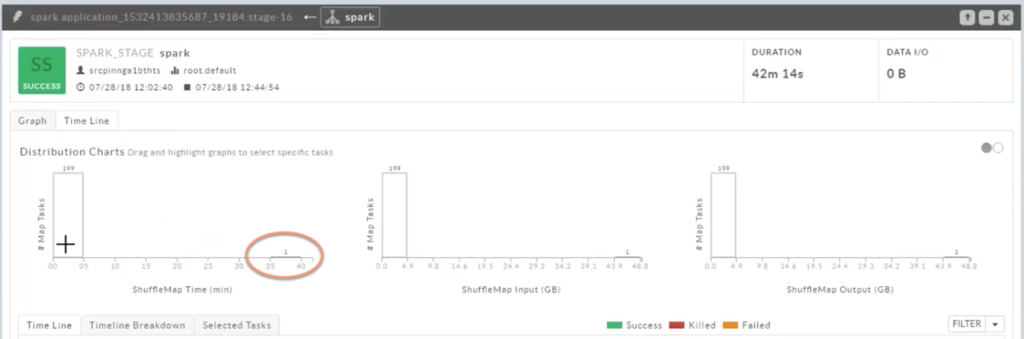
Once I’ve navigated to the stage, I can navigate to the Timeline view where the duration and I/O of each task within the stage are readily apparent. The histogram charts are very useful to identify outlier tasks, it is clear in this case that 199 tasks take at most 5 minutes to complete however one task takes 35-40 min to complete!
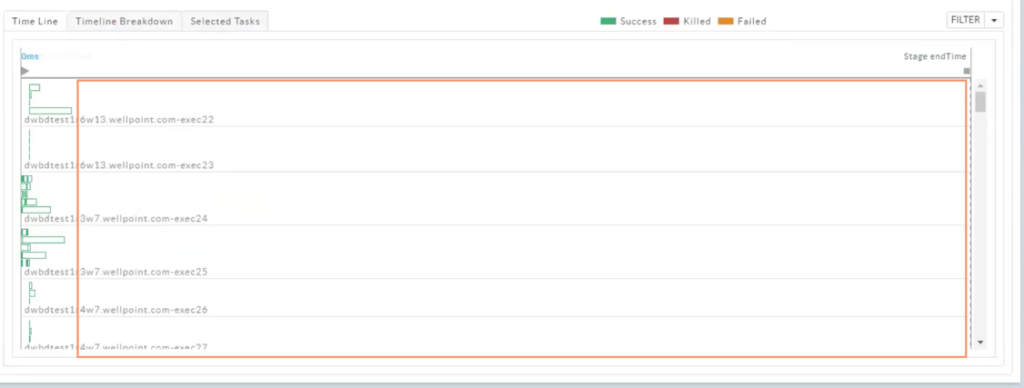
When we select the first bucket of 199 tasks, another clear representation of the effect of this skew is visible within the Timeline, many executors are sitting idle:
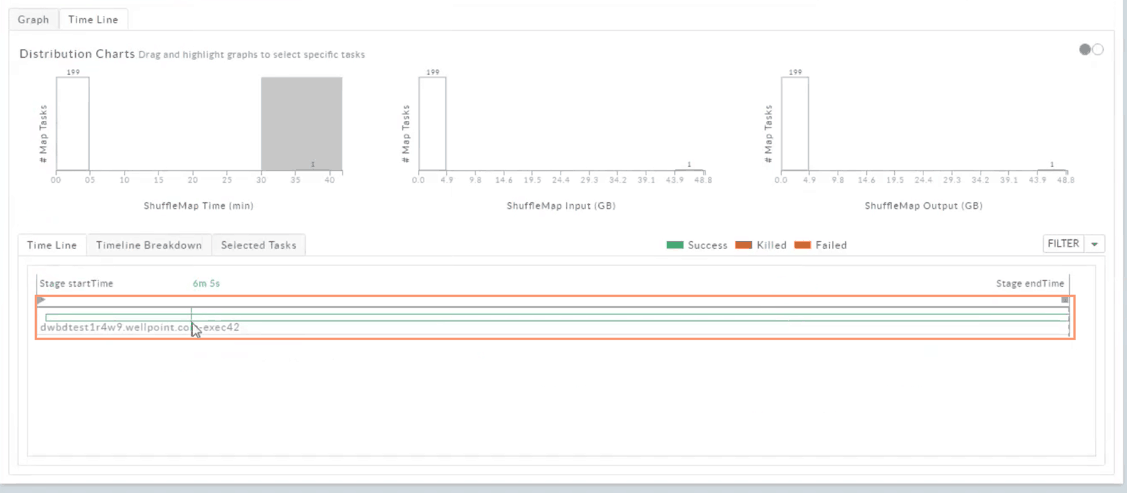
When we select the outlier bucket that took over 35 minutes to complete, we can see the duration of the associated executor is almost equal to the duration of the entire app:
We can also observe the bursting of containers at the time the longer executor started in the Graphs > Containers view. Adding more partitions via repartition() can help distribute the data set among the executors.
Unravel can provide recommendations for optimizations in some of the cases where join key(s) or group by key(s) are skewed.
In the below Spark SQL example two dummy data sources are used, both of them are partitioned.
The join operation between customer & order table is on cust_id column which is heavily skewed. Looking at the code it can easily be identified that key “1000” has most number of entries in the orders table. So one of the reduce partition will contain all the “1000” entries. In such cases we can apply some techniques to avoid skewed processing.
- Increase the spark.sql.autoBroadcastJoinThreshold value so that smaller table “customer” gets broadcasted. This should be done ensuring sufficient driver memory.
- If memory in executors are sufficient we can decrease the spark.sql.shuffle.partitions to accomodate more data per reduce partitions. This will finish all the reduce tasks in more or less in same time.
- If possible find out the keys which are skewed and process them separately by using filters.
Let’s try the #2 approach
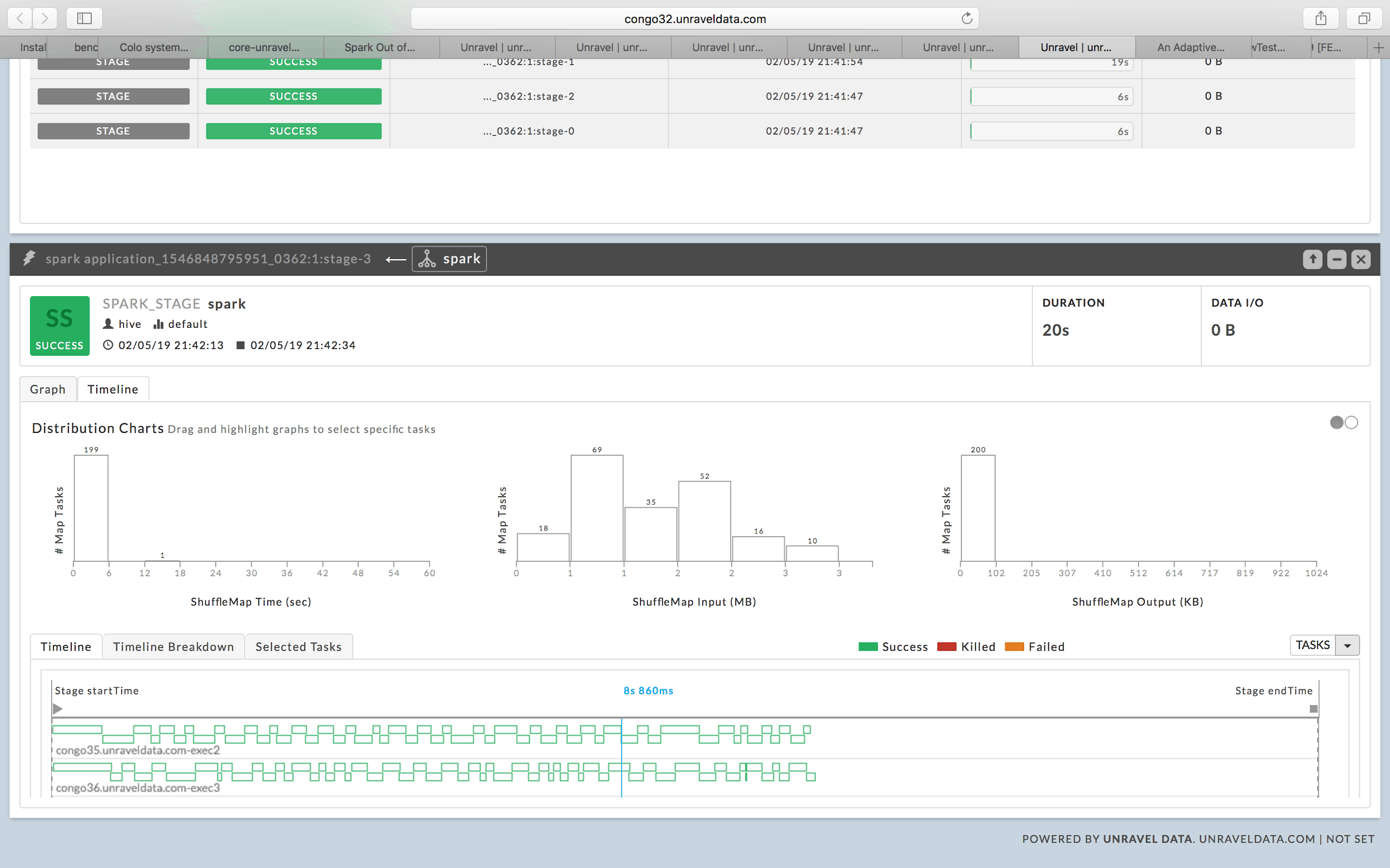
With Spark’s default spark.sql.shuffle.partitions=200.
Observe the lone task which takes more time during shuffle. That means the next stage can’t be started and executors are lying idle.
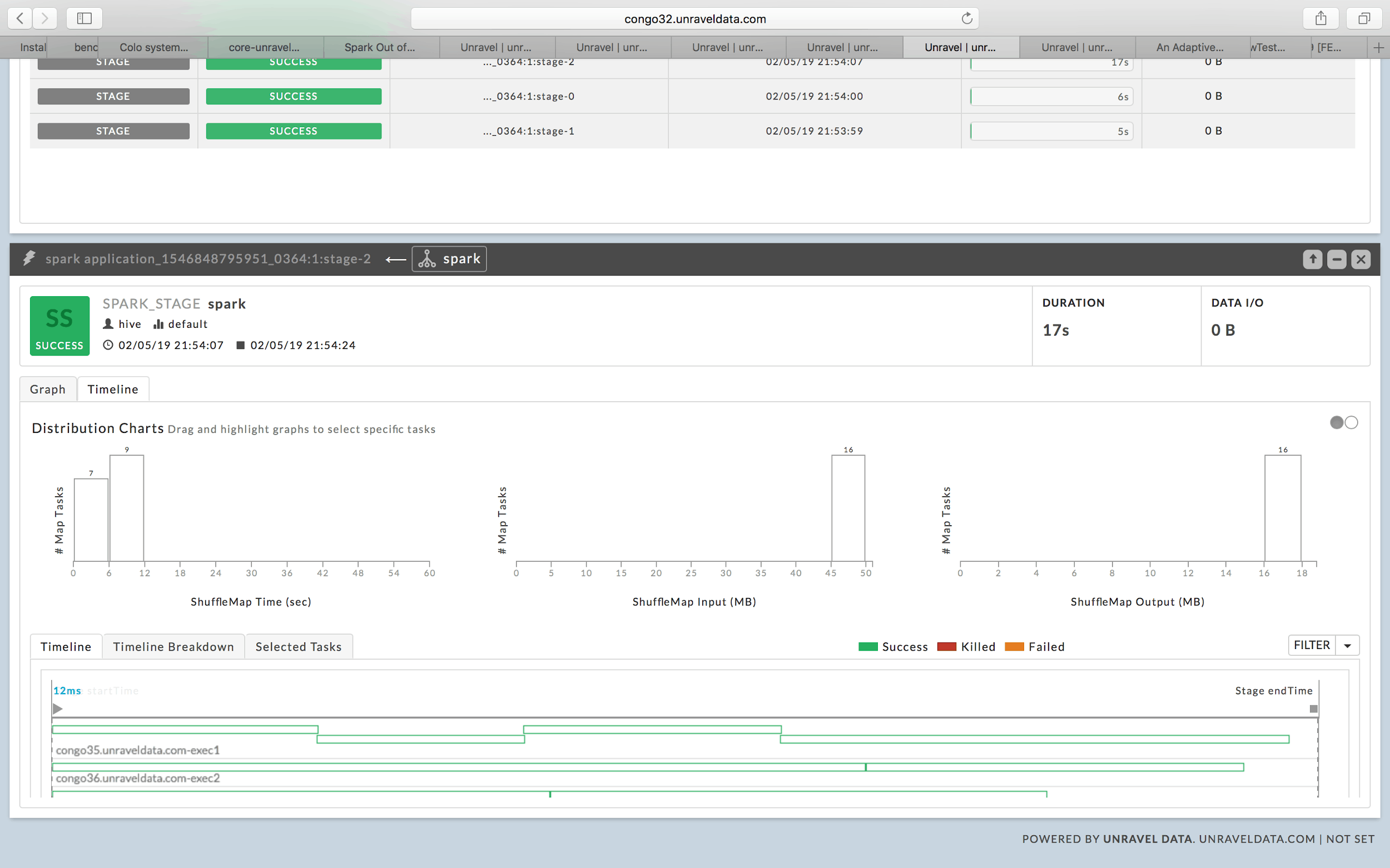
Now let’s change the spark.sql.shuffle.partitions = 10. As the shuffle input/output is well within executor memory sizes we can safely do this change.
In real-life deployments, not all skew problems can be solved by configurations and repartitioning. That may need underlying data layout modification. If the data source itself is skewed then tasks which read from these sources can’t be optimized. Sometimes at enterprise level its not possible as the same data source will be used from different tools & pipelines.
Sam Lachterman is a Manager of Solutions Engineering at Unravel.
Unravel Principle Engineer Rishitesh Mishra also contributed to this blog. Take a look at Rishi’s other Unravel blogs:
Why Your Spark Jobs are Slow and Failing; Part I Memory Management
Why Your Spark Jobs are Slow and Failing; Part I Data Skew and Garbage Collection